本篇是《深入剖析 Kubernetes》 的读书笔记,作者为张磊老师。
第五章《Kubernetes 编排原理》讲的内容都还比较实用,基本上都是在使用 Kubernetes 中就会接触到的概念和功能。
# Kubectl Cheatsheet
创建/更新一个 yaml 文件:
kubectl apply -f xxx.yaml查询资源列表:
kubectl get pods,然后可以接grep查询资源详情:
kubectl describe pod xxx导出 secret 的 yaml:
kubectl get secret <secret-name> -o yaml > secret.yaml启动一个临时的 pod:
kubectl run -it --rm --image=busybox --restart=Never debug -- sh回滚更新:
kubectl rollout undo deployment nginx-deployment
# Pod
一个 Pod 会有多个容器。同 Pod 的所有容器会在一台机器上运行。
Pod <-> 机器,管理容器、Namespace,以及网络、Volume 等资源
Container <-> 用户进程
每个 Pod 会有一个 Infra 容器,使用 pause 镜像,负责占据 Network、Namespace、Volume 等资源,然后给同 Pod 的其它容器使用。Infra 容器的生命周期和 Pod 的生命周期一致。
Pod 的一些配置,看到名字都能大概猜出来是什么意思。知道干嘛的就好,具体用的时候再来细查。不少配置在生产环境中很有用:
- VolumeMounts
- InitContainers
- HostAliases & Hostnames
- ImagePullPolicy (Always, IfNotPresent, Never)
- Lifecycle.PostStart & PreEnd
- Status & Condition (PodScheduled, Ready, Initialized, Unschedulable)
- ProjectedVolumes: Secret, ConfigMap, Downward API, ServiceAccountToken
- RestartPolicy (Always, OnFailure, Never)
- LivenessProbe & ReadinessProbe
- PodPreset
- Tolerations
# Taint & Toleration
Taint(污点)和 Toleration(容忍)是一个很有意思的模型。这两个词乍一看,和计算机科学没什么关系,以至于我第一时间完全不知道是什么功能。但是明白用处以后,又会觉得这两个词很生动形象。
简单来说,我们都知道 K8s 的核心工作之一是把 Pod 调度到 Node 上运行,而 Taint 和 Toleration 是定义一组规则来控制哪些 Pod 可以运行在哪些 Node 上。
Taint 是 Node 上的属性,它负责“污染” Node,让 Pod 不愿意运行在这个 Node 上。而 Toleration 是 Pod 的属性,它负责“容忍” Taint,让 Pod 可以运行在被污染的 Node 上。Taint 和 Toleration 模型的思想其实就是这两行。
Taint 和 Toleration 的用法,本文就不具体展开了。感兴趣的读者可以看看 K8s 官方文档。
污点和容忍度 | Kubernetes (opens new window)
kubernetes扩展:污点和容忍 - 知乎 (opens new window)
# PersistentVolumeClaim & PersistentVolume
Pod -> PVC -> PV
PVC 是定义接口(大小、AccessModes 等),PV 是实现(实际存储位置、认证信息等)。而 Pod 只需要在配置里面把 PVC 挂载到指定路径就行。
# StatefulSet & 主从 Pod
StatefulSet 是一个用起来比较复杂的概念,它解决的运维问题本身也比较复杂。简单来说,StatefulSet 可以用来部署“有状态应用”。
我对“有状态应用”的理解是:应用的状态是持久化的,且关键在于有一定的顺序性(拓扑结构),比如一主多从的 MySQL 集群。在部署这种集群时,每个节点需要知道自己的拓扑位置(节点是主还是从),可能还需要根据自己的位置做不同的初始化工作。
在 StatefulSet 中,Pod 的名字是有序的,比如 mysql-0、mysql-1、mysql-2。这样就可以通过 Pod 的名字来确定 Pod 的位置。在初始化时,可能需要在 yaml 里写 shell:
initContainers:
- name: init-mysql
image: mysql:5.7
command:
- bash
- "-c"
- |
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
if [ $ordinal -eq 0 ]; then
# 初始化主节点
else
# 初始化从节点
# DaemonSet
和 ReplicaSet、StatefulSet 一样,DaemonSet 控制了一堆 Pods。不同的是,DaemonSet 控制的 Pod 有一个特点:DaemonSet 保证每个 Node 上有且只有一个 DaemonSet 对应的 Pod。
所以 DaemonSet 适合部署一些需要在每个 Node 上运行的服务,比如日志收集、监控等。
# Job & CronJob
ReplicaSet、StatefulSet 和 DaemonSet 都运行了一些需要一直运行的 Pod,如果挂了会自动重启。而 Job 和 CronJob 则是运行一些一次性任务,运行完了会自动退出,状态变成 Completed;失败了以后可以配置自动重试,或者直接 Fail 掉。
Job 也有一些常用配置:
- RestartPolicy (OnFailure:失败后重启容器;Never:失败后创建新的 Pod)
- BackoffLimit
- ActiveDeadlineSeconds
- Parallelism
- Completions
CronJob 则是定时任务,可以配置 Cron 表达式。除了 Cron 以外,它还可以配置:
- ConcurrencyPolicy (Allow, Forbid, Replace) - 到时间点时,如果上一个任务还没执行完,这个任务是允许、禁止还是替换上一个任务
# RBAC
如果要在 Pod 里通过 Kubernetes API Server 读写 Pod 或者各种资源的信息(典型的例子是 Prometheus 这类性能监控),需要给这个 Pod 加权限。这时候就需要用到 RBAC。
Service Account <-> RoleBinding (ClusterRoleBinding) <-> Role (ClusterRole)
# 自定义 Controller、Operator
从这里开始就需要写点代码了。书里用的是 go,不过官方也支持使用 Python SDK 访问 Custom Resource,所以也可以写 Python。
定制资源 | Kubernetes (opens new window)
K8s 支持以插件的形式自定义资源(Custom Resource Definition,CRD),定义资源的时候需要启动这个资源的控制器(Controller),来处理这个资源的增删改查。
书中的例子定义了一个名为 network 的资源,启动 Controller 以后,使用这个资源的方法和其它资源一样:
kubectl get network
kubectl describe network my-network
kubectl apply -f example/example-network.yaml
关于 Controller 的架构,张磊老师把书里的原图放到了 Twitter (opens new window) 上。
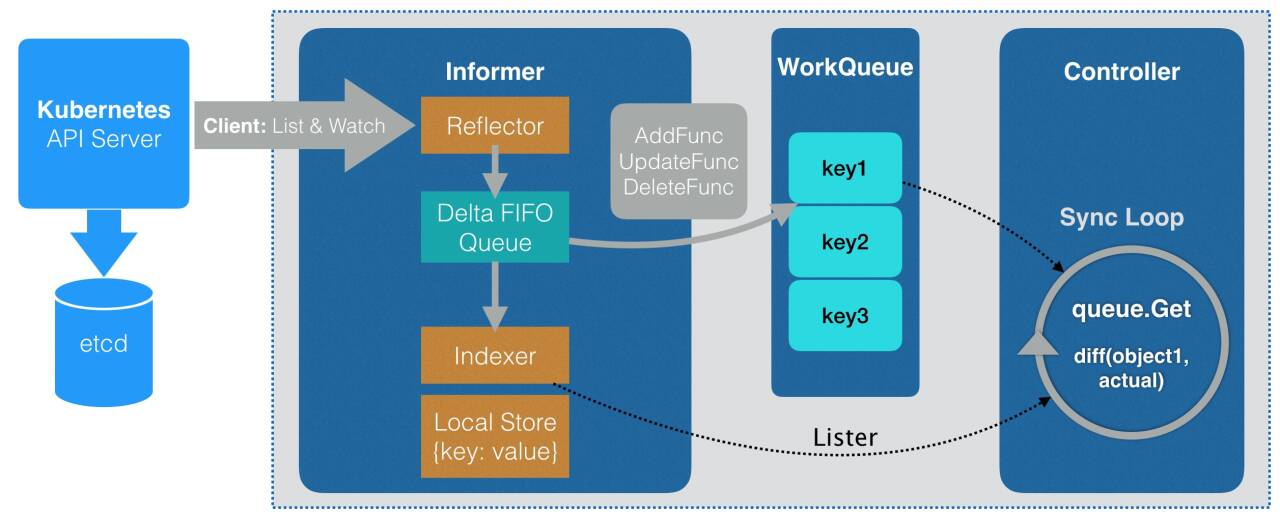
虚线框里是一个 Controller 的架构,包含 Informer、Work Queue 和最右边的业务逻辑实现(runWorker() 函数)。
在声明式 API 中,用户提交的 yaml 文件里包含了用户声明的所有资源。Informer 负责从 Kubernetes API Server 拿到用户声明资源的变化,然后把变化(增/删/改)的资源的 key(namespace/name)放到 Work Queue 里。Work Queue 里的任务会被 runWorker() 函数异步处理,处理完以后把 key 从队列里丢掉。
看起来很复杂,但是大部分代码都是可以自动生成的,只有最后 runWorker() 里的业务逻辑需要自己写。
Operator 模式 | Kubernetes (opens new window)
Operator 和自定义控制器很像,都是通过编程来实现更复杂、yaml 实现不了的资源管理。不过 Controller 更倾向于定义并管理一种新的资源,Operator 更倾向于把一堆运维步骤打包、自动化。
不过这块的实现真的很重。配环境、查文档、编程实现、测试 debug、部署运维,都是一大堆工作。还是等 yaml 配置不够用了再考虑吧。