以下知识均在后台开发面试中实际出现过、总结而来。
# C++
# 多态的实现
即虚函数表。
# STL 容器库
容器库 - cppreference.com (opens new window)
# unordered_map 和 map 的区别
略。
# multimap 和 map 的区别
略。
# 智能指针
智能指针(现代C++) | Microsoft Docs (opens new window)
智能指针是对普通指针的一个封装。普通指针 new 了以后一定要 delete,而智能指针是一个类,当这个类的对象超出作用域以后,会自动调用析构函数,因此不再需要 delete,也不会因为忘记 delete 而发生内存泄露。
智能指针和普通指针的对比:
void UseRawPointer()
{
// Using a raw pointer -- not recommended.
Song* pSong = new Song(L"Nothing on You", L"Bruno Mars");
// Use pSong...
// Don't forget to delete!
delete pSong;
}
void UseSmartPointer()
{
// Declare a smart pointer on stack and pass it the raw pointer.
unique_ptr<Song> song2(new Song(L"Nothing on You", L"Bruno Mars"));
// Use song2...
wstring s = song2->duration_;
//...
} // song2 is deleted automatically here.
智能指针体现什么机制:封装。
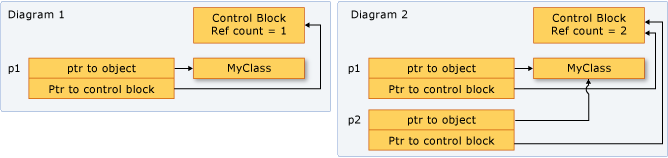
unique_ptr:unique_ptr的出现是为了替代 C++98 的auto_ptr(而auto_ptr于 C++11 中被弃用)。如果不知道用什么,默认用unique_ptr就对了。unique_ptr只占一个指针大小的空间shared_ptr:shared_ptr的管理类似于 Python 的垃圾回收机制:对变量进行计数(如下图)。拷贝构造auto sp3(sp2);和赋值auto sp4 = sp2;都会使得计数++。shared_ptr占两个指针大小的空间weak_ptr:shared_ptr中如果有循环引用,导致二者的计数都不为 0,会导致内存泄露。可以在引用的地方使用weak_ptr并将shared_ptr赋给它,这不会使得shared_ptr计数++,之后能被正确地回收。例子 (opens new window) 例子2 (opens new window)
# Java
参考:《Spring 技术内幕:深入解析 Spring 架构与设计原理》(第 2 版) (opens new window)
# Spring IoC
# IoC 和 DI 的概念
先说两个概念:
- IoC (Inversion of Control):控制反转。
- DI (Dependency Injection):依赖注入。
控制反转是目的、结果,依赖注入是实现控制反转的手段、方法。可以使用依赖注入或依赖查找实现 IoC,但还是依赖注入比较主流。
# 优点
- 资源不再由我们进行管理,而是交给框架进行管理。比如我们写了
UserController、UserService,在实际运行时,我们不需要进行new UserController()等代码,而是交给框架进行创建和销毁。 - 降低耦合度。说实话我不太赞同这个优点是 IoC 带来的,我认为这个是将接口和实现分离而带来的。
- 解决循环依赖。如果两个 Service 有互相依赖,如果让我们让我们负责创建这两个 Service,我们在 ServiceA 的构造函数中会
new ServiceB(),而在 ServiceB 的构造函数中会new ServiceA(),导致循环依赖。Spring 的 IoC 的确解决了循环依赖的问题,不过 Spring 2.6 中会默认禁止循环依赖,避免用户不小心创建循环依赖的 Beans。
# 原理
基本概念:
- Bean:需要由 Spring IoC 容器管理的对象,如
UserController、UserService - BeanFactory:Spring IoC 容器的接口,提供获取 Bean 对象、Bean 的基本信息(以 BeanDefinition 的形式保存)等接口
- ApplicationContext:BeanFactory 的子接口,除了提供 BeanFactory 的所有接口外,还提供了更多功能(如 Spring AOP、Message Source、事件广播器)。Spring 应用的数据都保存在 ApplicationContext 的实现类中。有意思的是,这个实现类的 BeanFactory 相关接口是通过代理模式实现的(类里存储了一个 BeanFactory 对象)。
- Processor:Spring IoC 中拥有处理能力的工具类。Spring 中有两种:
BeanFactoryPostProcessor和BeanPostProcessor。前者用于干预 BeanFactory 的创建过程,后者用于干预 Bean 的创建过程(如实现@Autowired、AOP 等)。二者的接口定义如下:
public interface BeanFactoryPostProcessor {
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
}
public interface BeanPostProcessor {
Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException;
Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException;
}
Spring Boot 通过在 main 函数里调用 SpringApplication.run(),完成 Spring 容器的初始化,其过程可以参考下面的思维导图。

下面是可以用于面试的回答模板。
- 初始化一个 Spring Boot 应用,可以使用
SpringApplication.run()函数。这个函数主要做了两件事:实例化 ApplicationContext,和调用refresh()函数:实例化所有非懒加载的单例Bean - 在实例化 ApplicationContext 时,Spring 会实例化 BeanFactory;然后将几个自带的 Processor 注册到容器中,之后会在
refresh()函数中用到 refresh()函数的核心有 5 个步骤:- 执行所有
BeanFactoryPostProcessor - 注册所有的
BeanPostProcessor,这个过程会扫描所有的 Bean,并保存到 BeanFactory 中 - 初始化 MessageSource
- 初始化事件广播器
- 实例化剩余的
非懒加载的单例Bean。这里会遍历 Bean 的列表,通过查询 Bean 的定义,排除掉不满足条件的 Bean,然后对剩下的 Bean 调用getBean()。
- 执行所有
getBean函数首先会检查BeanFactory中是否已经实例化这个 Bean,如果已经实例化则直接返回实例化的对象;如果没有,则会调用createBean创建 Bean。createBean函数分为三个步骤:- 利用反射,拿到这个 Bean 的所有构造函数,然后根据传入的参数选择一个构造函数进行实例化
- 实例化以后将其存入 BeanFactory
- 调用
populateBean装配当前 Bean 关联的其它 Bean。通过反射找到这个 Bean 里需要装配(如@Autowired)的字段,然后调用getBean()递归地获取 Bean。
# 如何解决循环依赖
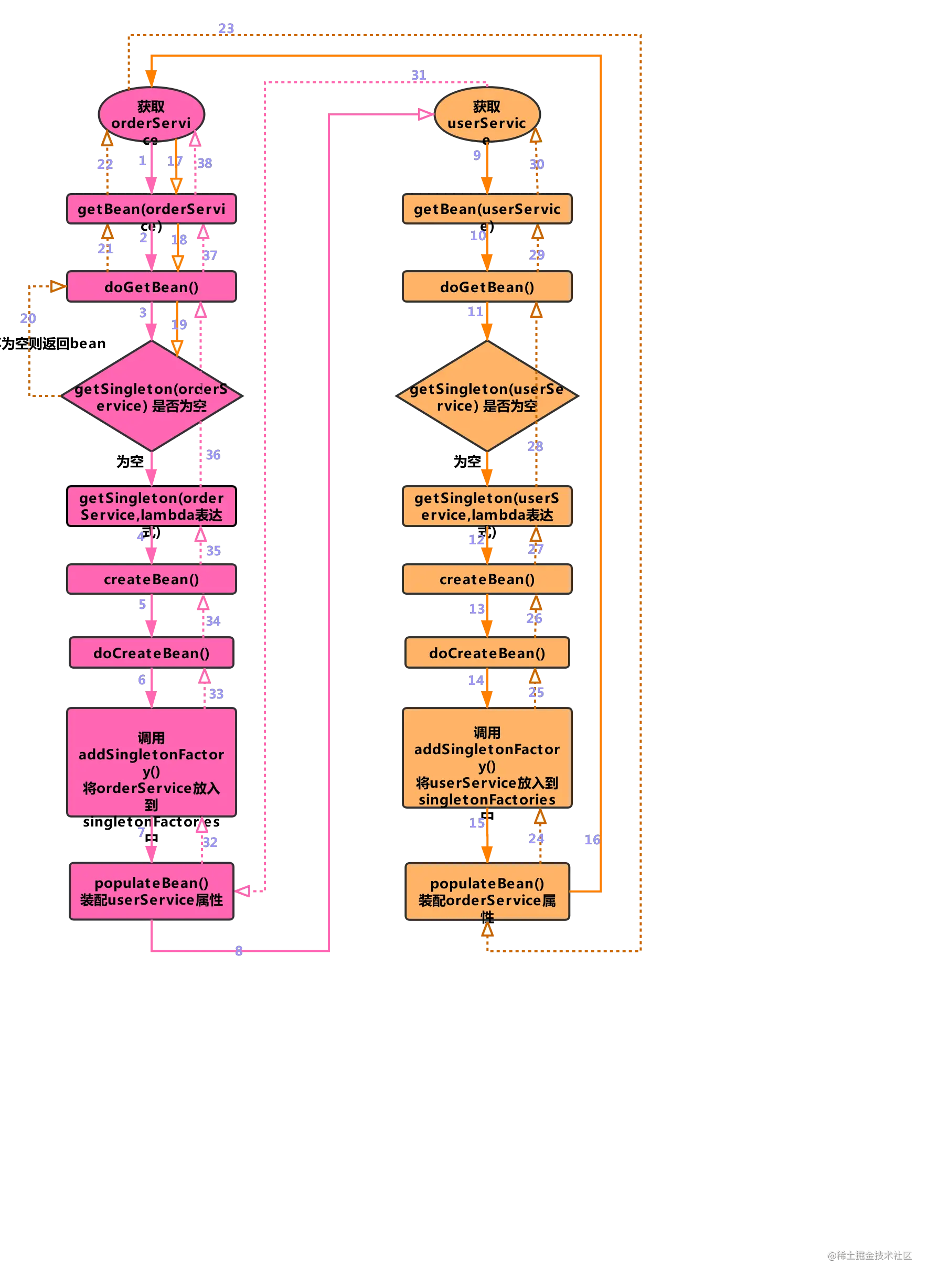
Spring 通过调用 getBean() -> createBean() -> populateBean() -> getBean() 递归地创建 Bean。但创建了一个 Bean 以后,Spring 会将其存到 BeanFactory 中,下次 getBean() 时会直接返回该实例。因此每个 Bean 只会被创建一次,不会无限递归。
下面是从一个来自掘金的详细流程图,可供参考。
# Java 动态代理 & Spring AOP
参考:《Spring技术内幕:深入解析Spring架构与设计原理》第三章 —— Spring AOP 的实现
AOP 是 Aspect-Oriented Programming(面向方面编程),和 OOP(面向对象编程)都是为了使代码和功能更模块化。OOP 利用继承,很容易实现纵向的模块化(为一个类的所有子类添加相同的功能和代码),而 AOP 的出现就是为了实现横向的模块化,它可以按照指定的规则,给满足条件的函数加相同的功能和代码。例如,AOP 常用于日志等场景,可以为指定的所有方法添加日志功能。
# AOP 使用场景
- Auth(认证)
- Cache(缓存)
- Context passing(上下文传递)
- Logging(日志)
# AOP 相关概念
# Advice
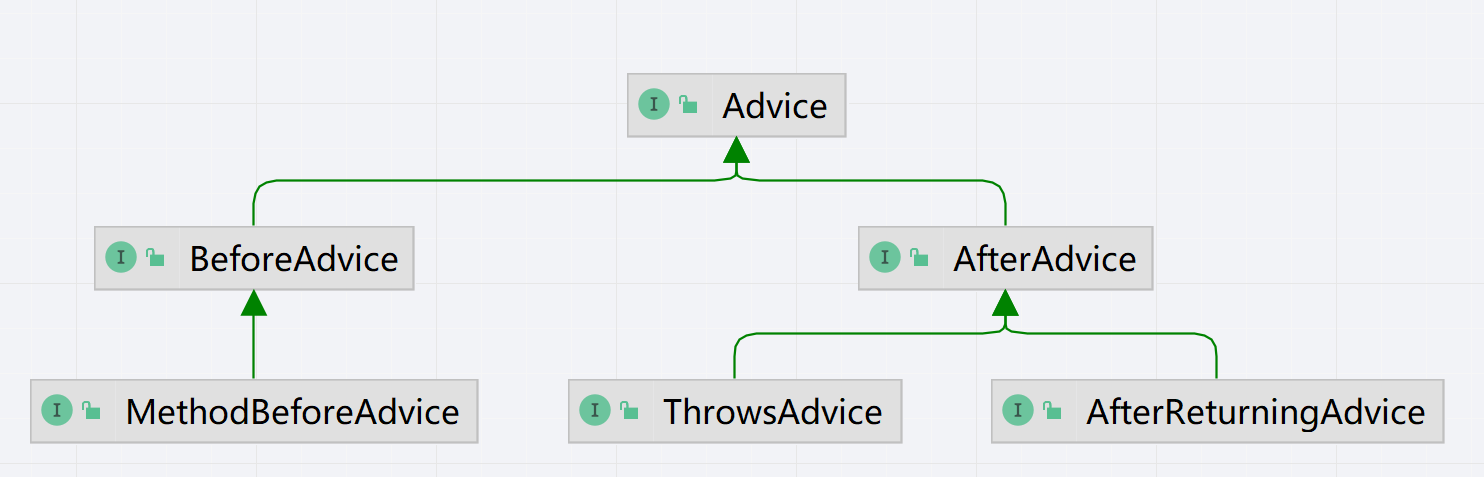
Advice(通知)定义了 AOP 中“相同的功能和代码”。直接理解这个概念会相当抽象,所以我们看看 Advice 的三个核心的子接口:MethodBeforeAdvice、AfterReturningAdvice 和 ThrowsAdvice 的代码。
public interface MethodBeforeAdvice extends BeforeAdvice {
void before(Method method, Object[] args, @Nullable Object target) throws Throwable;
}
public interface AfterReturningAdvice extends AfterAdvice {
void afterReturning(@Nullable Object returnValue, Method method, Object[] args, @Nullable Object target) throws Throwable;
}
/**
* <p>There are not any methods on this interface, as methods are invoked by
* reflection. Implementing classes must implement methods of the form:
*
* <pre class="code">void afterThrowing([Method, args, target], ThrowableSubclass);</pre>
*/
public interface ThrowsAdvice extends AfterAdvice {
}
看到 Advice 接口下面定义的函数,其实就比较好理解了。接口里定义的是回调函数,比如 MethodBeforeAdvice.before() 就是在目标函数被调用前,会调用这个函数;AfterReturningAdvice.afterReturning() 就是在目标函数被调用后,会调用这个函数;而 ThrowsAdvice.afterThrowing() 就是在目标函数抛异常以后,会调用这个函数。当我们把“相同的功能和代码”写到这几个回调函数里,就可以在不同的函数执行前后,执行这些代码了。
# PointCut
Advice 定义了需要在不同函数的先后执行的“相同的功能和代码”,而 PointCut(切入点)定义了哪些函数需要执行。说白了,PointCut 就是一个筛选器。我们还是直接看 PointCut 接口的定义。
public interface ClassFilter {
boolean matches(Class<?> clazz);
}
public interface MethodMatcher {
boolean matches(Method method, Class<?> targetClass);
boolean matches(Method method, Class<?> targetClass, Object... args);
}
public interface Pointcut {
ClassFilter getClassFilter();
MethodMatcher getMethodMatcher();
}
ClassFilter 定义了筛选类的类,ClassFilter.matches 接收一个类,返回 boolean 表示是否匹配;MethodMatcher 定义了筛选方法的类,MethodMatcher.matches 接收一个方法(还有它的类、以及调用方法时的参数),返回 boolean 表示是否匹配。
很显然,PointCut 就是负责筛选类和方法。
# Advisor
Advisor(通知器)做的事情,就是将 PointCut 和 Advice 结合起来,这样就可以表达“给满足条件的函数加相同的功能和代码”的意思。
public interface Advisor {
Advice getAdvice();
}
public interface PointcutAdvisor extends Advisor {
Pointcut getPointcut();
}
# AOP 的实现
AOP 的核心技术是动态代理(Dynamic Proxy)。代理是常见的设计模式,它基于实际的对象 realSubject 创建一个拥有相同方法的对象 proxySubject(代理对象也被称为增强过的对象),并在今后的操作中代替 realSubject。Python 的装饰器就是类似的设计模式。
静态代理和动态代理的区别在于,静态代理需要我们手写 proxySubject 的类,而动态代理则不需要,可以动态生成类,并为我们实例化一个 proxySubject。
Java 中有两种动态代理的方案,一是使用 JDK 自带的动态代理,另一种是使用 cglib 提供的动态代理。
JDK 和 cglib 的动态代理在使用上最大的区别在于:JDK 动态代理只能通过实现接口的方式进行代理(所以目标类必须实现一个接口,而 JDK 代理类也会实现这个接口);而 cglib 代理可以通过创建目标类的子类进行代理,不需要目标类实现接口。因此,JDK 只能代理实现了接口的类,cglib 可以代理没有接口的类,但 cglib 不能代理 final 类和类中的 final 方法。
代理是 AOP 的第一步,在完成代理后,还需要启动代理对象的 Interceptor(拦截器)将 Advice 的代码进行织入。
# Spring AOP 的自调用问题
读 Spring 文档的时候突然发现一个网上没怎么提到过的问题:自调用(self-invocation),比如在 this.foo() 方法中调用了 this.bar()。
考虑下面这个情形:我们编写了一个 RealSubject,其中 foo() 方法会调用 bar()。随后对这个类进行代理。
class RealSubject implements Interface {
public void foo() {
bar();
}
public void bar() {
//...
};
}
public class Main {
public static void main(String[] args) {
ProxyFactory factory = new ProxyFactory(new RealSubject());
factory.addInterface(Interface.class);
factory.addAdvice(new RetryAdvice());
factory.setExposeProxy(true);
RealSubject proxySubject = (RealSubject) factory.getProxy();
// this is a method call on the proxy!
proxySubject.foo();
}
}
调用链是这样的:
proxySubject.foo() -> realSubject.foo() -> realSubject.bar()
这里的问题在于,realSubject.foo() 调用 bar() 时,调用的是 this(即 realSubject) 的 bar(),没有经过代理就调用了 bar() 方法,会导致对 bar() 方法添加的 Advice 不会生效。
Spring 给出了三种解决方案:
- 重构
RealSubject的代码,回避掉自调用和 Advice 需要同时发生的情况。 - 将 Spring AOP 的逻辑加入
RealSubject.foo()中(但这样的侵入性很强,不推荐)
class RealSubject implements Interface {
public void foo() {
((RealSubject) AopContext.currentProxy()).bar();
}
public void bar() {
//...
};
}
- 改用 AspectJ 的 AOP 方案,因为 AspectJ 的 AOP 不是基于代理的,就不存在这个问题。
# Spring 事务
Data Access | Spring (opens new window)
Spring 提供了事务管理。其本质是调用 JDBC 提供的 TransactionManager,最终落实到数据库的事务上。
可以在方法前加 @Transactional 来使用 Spring 事务。标注了 @Transactional 的方法会被代理,用以在实际执行前开启事务,成功结束后提交,抛出异常时回滚。
除了使用 @Transactional 这种声明式的事务管理(Declarative Transaction Management)以外,也可以使用 TransactionManager 或 TransactionTemplate 编程式的事务管理(Programmatic Transaction Management)。
public class SimpleService implements Service {
@Autowired
private TransactionManager transactionManager;
public Object someServiceMethod() {
TransactionStatus status = transactionManager.getTransaction(def);
try {
// put your business logic here
} catch (MyException ex) {
transactionManager.rollback(status);
throw ex;
}
transactionManager.commit(status);
}
}
public class SimpleService implements Service {
@Autowired
private TransactionTemplate transactionTemplate;
public Object someServiceMethod() {
return transactionTemplate.execute(new TransactionCallback() {
// the code in this method runs in a transactional context
public Object doInTransaction(TransactionStatus status) {
updateOperation1();
return resultOfUpdateOperation2();
}
});
}
}
# 数据结构
# 快排算法、快排的时间复杂度(平均、最坏)
# Java 自带数据结构
// 排序
int[] a;
Arrays.sort(a);
List<Integer> arr;
Collections.sort(arr);
// 队列、优先队列
Queue<Integer> queue = new ArrayDeque<>();
Queue<Integer> priorityQueue = new PriorityQueue<>();
queue.add(1);
assert queue.remove() == 1;
// 栈
Stack<Integer> stack = new Stack<>();
stack.add(1);
assert stack.pop() == 1;
// Map
Map<Integer, Integer> map = new HashMap<>();
map.put(1, 2);
for (Map.Entry<Integer, Integer> entry: map.entrySet()) {
assert entry.getKey() == 1;
assert entry.getValue() == 2;
}
map.remove(1);
// Set
Set<Integer> set = new HashSet<>();
set.add(1);
assert set.contains(1);
for (Integer i: set) {
assert false;
}
set.remove(1);
# 数据库
# MySQL 数据库引擎
- MyISAM:读性能高,但不支持外键、行级锁和事务,MySQL 5.5 默认
- InnoDB:读性能稍弱,支持外键、行级锁和事务,MySQL 5.5.5 及以后默认
二者都使用 B+ 树作为存储的数据结构。
# B 树和 B+ 树
# B 树
B 树 | 维基百科 (opens new window)
面试官问你B树和B+树,就把这篇文章丢给他- SegmentFault 思否 (opens new window)
先要纠正两个常见误区:
- B 树 (B-Tree) 不是二叉树 (Binary Tree)。B 的全称,可能起源于其发明者 (opens new window),不过理解成平衡 (balanced) 或宽的(broad) 或 茂密(bushy) 也不错。
- 没有 B 减树!B 减树的出现可能是翻译人员错误地将 B 树 (B-Tree) 翻译成了 B 减树。
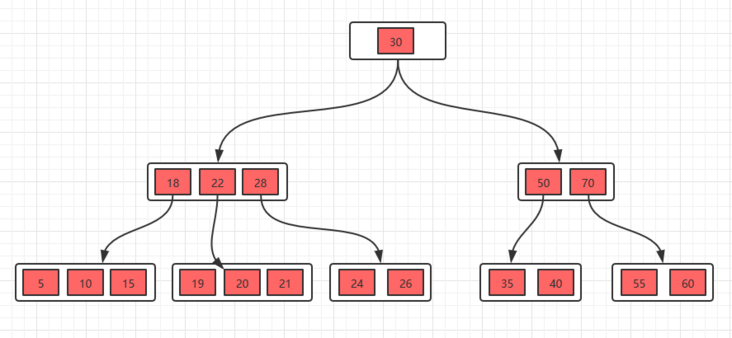
概述:B 树是是一种自平衡的树,能够保持数据有序(听起来就是在说平衡二叉树)。其与平衡二叉树的不同在于,B 树的一个节点可以拥有 2 个以上的子节点,且节点数在某范围内可变。这样的好处有:
- 子结点的增多能够降低深度,减少定位记录时所经历的中间过程,运用在磁盘、数据库中可以加快存取速度;
- 由于节点数在范围内可变,因此 B 树不需要像其他平衡二叉查找树那样经常进行平衡
定义:一棵 m 阶 B 树的定义:
- 每个节点最多有
m-1个 key; - 根节点最少可以只有
1个 key,非根节点至少有m/2个 key(根节点的 key 数量范围:[1, m-1],非根节点的 key 数量范围:[m/2, m-1]。); - 每个节点中的 key 都按照从小到大的顺序排列,每个 key 的左子树中的所有 key 都小于它,而右子树中的所有 key 都大于它;
- 所有叶子节点都位于同一层(即根节点到每个叶子节点的长度都相同);
- 每个节点都存有索引和数据,也就是对应的 key 和 value。
B 树插入的规则:插入的时候,判断当前结点key的个数是否小于等于 m-1,如果满足,直接插入即可,如果不满足,将节点的中间的 key 将这个节点分为左右两部分,中间的节点放到父节点中即可。
# B+ 树
B+ 树具有上述 B 树的前四个特点。除此之外,B+ 树还有以下特点:
- B 树的所有结点都存储数据,而 B+ 树只有叶子结点存储数据,内部节点(或非叶子结点、索引节点)只存放索引。在节点空间大小一定的前提下,B+ 树一个结点能存的索引数远大于 B 树一个结点能存的数据的量,这使得 B+ 树的高度远低于 B 树。
- B+ 树每个叶子结点存有下一个叶子结点的指针,而 B 树无,所以所有叶子结点形成了一条有序链表,遍历整棵树只需要遍历链表,而不需要从树根往下遍历。
B+ 树较 B 树的优点就是遍历快吧。
# 慢查询
MySQL索引原理及慢查询优化- 美团技术团队 (opens new window)
慢查询:超过指定时间的 SQL 语句查询。
优化方法:
- 使用
explain语句查看慢查询的查询过程(有无使用索引等) - 添加索引、修改索引(如先查区分度大的)
- 分库、分表
# 聚簇索引 & 非聚簇索引
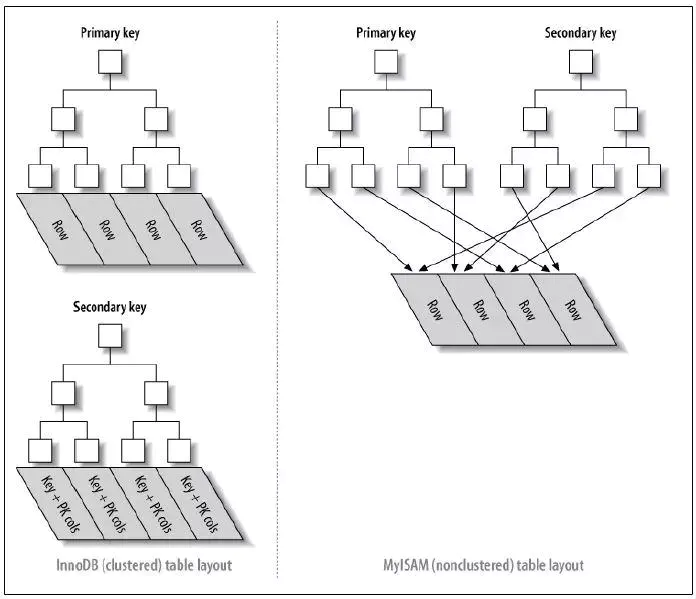
InnoDB 主键使用的是聚簇索引。
- 非聚簇索引(二级索引、辅助索引):表数据和索引分成两部分存储,叶子结点存主键和索引键
- 聚簇索引:表数据和主键一起存储,主键索引的叶子结点存行数据 (包含主键值)
聚簇索引的优点简单说就是三个字:查询快
- 查询非主键数据时,使用非聚簇索引查询到主键后,还需要使用聚簇索引查询数据
- 非聚簇索引查询主键时不需要进行二次查询,查询其他键时需要二次查询
- 查询范围的数据时,如果命中的是聚簇索引可以一并把范围内的数据取出来,但命中的是非聚簇索引的话需要再在聚簇索引中查询多次
聚簇索引的缺点简单的说也是三个字:插入、更新慢
- 插入速度依赖插入顺序,如果是随机插入在表中间,插入的过程会很慢;如果直接插入到表末尾的话就会比较快
- 更新主键慢,因为需要移动被更新的行
# InnoDB 为什么推荐使用 auto_increment 作为主键
- auto_increment 保证能新加入的数据的主键永远是最大的,加入的数据会被放在最后。在写入量大的时候,插入数据时是连续写入,而不是随机 I/O
- auto_increment 使得主键和业务分离,这样即便业务上出现调整,也不需要重构数据库
# 回表、索引覆盖、索引下推
参考:
在Mysql中,什么是回表,什么是覆盖索引,索引下推? - 知乎 (opens new window)
第26期:索引设计(索引下推) - SegmentFault 思否 (opens new window)
# 回表
回表的概念是和非聚簇索引相关的。非聚簇索引只存储了主键和索引键,查询时如果用到了某个索引,但需要查询的字段不全在索引上,就需要回到聚簇索引的这张表上再查一遍。
举个栗子:一个表上有主键 id、字段 name(建立了关于 name 的索引)、另外还有普通字段 gender 和 phone。
如果我们 SELECT id FROM table WHERE name = 'query',在索引表上查到满足条件的 name 和 id 就够了,不需要回表;
如果改为 SELECT gender FROM table WHERE name = 'query',则需要回表。
# 索引覆盖
索引覆盖是解决回表的方法。如果我们把 name 的索引改为 (name, gender) 的联合索引,同样是 SELECT gender FROM table WHERE name = 'query' 的查询就能在索引表上直接查到满足条件的 gender,避免了回表的操作。
# 索引下推
索引下推是 MySQL 5.6 起引入的一个内部优化。
假设现在的索引是 (name, gender),需要查询的语句为
SELECT *
FROM table
WHERE name = 'query'
AND gender = 2
AND phone IS NOT NULL;
索引查询时,如果没有索引下推,则根据最左匹配原则,索引会筛选出 name = 'query' 条件对应的 id,然后回表,在主表中使用 gender = 2 AND phone IS NOT NULL 过滤结果。
这里的问题在于,索引既然包含 gender 字段,在索引表里其实可以使用 name = 'query' AND gender = 2 进行筛选,减少回表的数据量,在回表中再使用 phone IS NOT NULL 过滤结果。索引下推就是这样一个作用:尽量充分利用索引表进行筛选,最后再在主表中完成剩余的筛选。
# 事务的 ACID
ACID,是指数据库管理系统 (DBMS) 在写入或更新资料的过程中,为保证事务 (transaction) 是正确可靠的,所必须具备的四个特性:
- 原子性 (atomicity):一个事务要么全做要么全不做;
- 一致性 (consistency):数据处于一种有意义的状态,这种状态是语义上的而不是语法上的。最常见的例子是转帐:从帐户 A 转一笔钱到帐户 B 上,如果帐户 A 上的钱减少了,而帐户 B 上的钱却没有增加,那么我们认为此时数据处于不一致的状态;
- 隔离性 (isolation):一个事务不影响其他事务的运行效果;
- 持久性 (durability):事务一旦提交,则其结果就是永久性的,即使故障也能恢复。
从数据库层面,数据库通过原子性、隔离性、持久性来保证一致性。也就是说 ACID 四大特性之中,C 是目的,AID 是手段,是为了保证一致性,数据库提供的手段。
# 事务的原子性和持久性的保证
- 将所有事务开始、提交、终止,以及数据的更新操作(记录数据更新前的值即前像,或更新后的值即后像)计入 log
- 系统崩溃后重启,先读取日志对已提交的事务进行 REDO(保证持久性)
- 然后对尚未提交的的事务进行 UNDO(保证原子性)
# InnoDB 事务隔离级别
MySQL 事务隔离级别和锁– IBM Developer (opens new window)
SQL 标准定义了四种隔离,隔离程度由低到高依次为:
- 读未提交/脏读:未提交事务的数据也可以被读,这也被称为脏读;
- 读提交/不可重复读:提交了的东西就可以被读,但若一个事务两次读取过程中,有事务更新了数据,会导致不可重复读;
- 可重复读/幻读(默认):同一个事务中,
select的结果是事务开始时的状态,因此可重复读。但由于insert语句等不受影响,所以可能出现幻读(本事务开始后,别的事务提交了数据pk=1,本事务select不到pk=1,但insert pk=1会报错主键冲突,像是读到了幽灵) - 序列化:如果要完全解决上面的三种问题,就只能让事务串行化了,也就是把多个事务变成一个序列。
| 有/无问题 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 有 | 有 | 有 |
| 读提交 | 无 | 有 | 有 |
| 可重复读 | 无 | 无 | 有 |
| 序列化 | 无 | 无 | 无 |
# 数据库并发控制
见 数据库并发控制。
# 计算机网络
# OSI 七层
就是把 TCP/IP 五层中的“应用层”拓展为(自底向上)“会话层”、“表示层(加密相关,如 TLS)”、“应用层”。
应用层(例:HTTP 协议)
表示层(例:TLS 协议)
会话层
传输层(例:TCP 协议)
网络层(例:IP 协议)
链路层(例:OCSP 协议)
物理层
# TCP 三次握手与四次挥手
TCP 三次握手与四次挥手 (opens new window)
三次握手:
- 客户端:发送
SYN,进入SYN_SENT状态 - 服务器:收到包后发送
SYN ACK,进入SYN_RCVD状态 - 客户端:收到包后发送
ACK,进入ESTABLISHED状态(服务器接收后也进入ESTABLISHED状态)
三个包的 seq 和 ACKnum 数值有如下关系:
SYN ACK的 ACKnum =SYN的 seq+1ACK的 ACKnum =SYN ACK的 seq+1
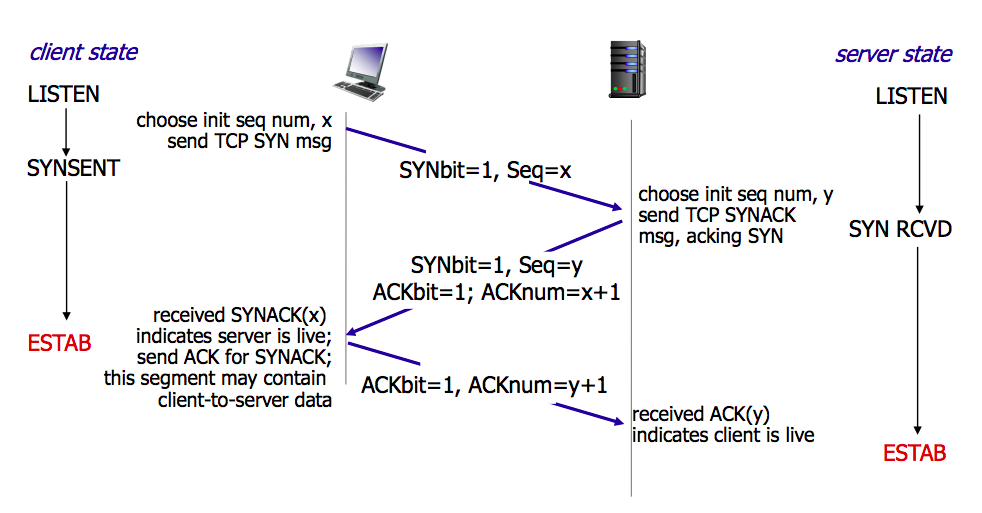
四次挥手并不一定是客户端发起,也可以由服务端发起。故下面用 主动关闭 和 被动关闭 称呼:
- 主动关闭方:发送最后一个数据包后,发送
FIN,进入FIN_WAIT_1; - 被动关闭方:收到包后发送
ACK,进入CLOSE_WAIT;客户端收到后进入FIN_WAIT_2,此时客户端到服务端的单方连接被关闭; - 被动关闭方:发送最后一个数据包后,发送
FIN,进入LAST_ACK; - 主动关闭方:收到包后发送
ACK,进入TIME_WAIT,一段时间后关闭通信;服务端收到后立即关闭通信。
可以理解为两对 FIN - ACK,且每个 ACK 的 ACKnum = 对方的 FIN 的 seq+1。
CLOSE_WAIT可以理解成对方主动关闭了连接,但本方还没有关闭,在等待关闭连接 (wait close);TIME_WAIT首先发出 FIN 的一侧,如果给对侧的 FIN 响应了 ACK,那么就会超时等待 2*MSL 时间,然后关闭连接(time wait)。在这段超时等待时间内,本地的端口不能被新连接使用;避免延时的包的到达与随后的新连接相混淆。RFC793 定义了 MSL 为2分钟(即TIME_WAIT等待 4 分钟)。

被动关闭的一方也可以把 ACK 和 FIN 合并为 FIN ACK,实现三次挥手。
# TCP 流量控制
TCP流量控制、拥塞控制 (opens new window)
- 流量控制:考虑到可能接收方处理的比较慢,需要限制发送方的发送速度。方法是,接收方发回的 ACK 中会包含自己接收窗口的大小。
- 流量控制死锁:当发送者收到了一个窗口为 0 的应答,便停止发送,等待接收者的下一个应答。但如果之后接受者发送的窗口不为 0 的应答在传输过程丢失,发送者一直等待下去,而接收者以为发送者已经收到该应答,等待接收新数据,这样双方就相互等待,从而产生死锁。
- 流量控制死锁避免:TCP 使用持续计时器。每当发送者收到一个零窗口的应答后就启动该计时器,时间一到便主动发送报文询问接收者的窗口大小。若接收者仍然返回零窗口,则重置该计时器继续等待;若窗口不为 0,则表示应答报文丢失了,此时重置发送窗口后开始发送。
# TCP 快速重传
- 在没有快速重传机制下,如果发送方的某报文丢失,即使接受方发送了多个重复确认,发送方仍需等待重传计时器到期才会重传;
- 快速重传机制下,发送方一旦收到三个重复确认,就重传报文,无需等待计时器到期。
# TCP 拥塞控制
TCP流量控制、拥塞控制 (opens new window)
发送方维持一个变量:拥塞窗口 (congestion window, cwnd),取决于网络拥塞情况,且动态变化。
发送方使自己的发送窗口为 。
- 慢启动阶段,
cwnd=1,每成功传输一次则cwnd*=2,直至 cwnd 到达慢启动阈值 (slow-start threshold, ssthresh),进入拥塞避免状态。 - 拥塞避免状态,每成功传输一次则
cwnd++ - 任何时刻,出现发送方对某报文的计时器超时,令
ssthresh=cwnd/2,cwnd=1,重新进入慢启动 - 快速恢复:任何时刻,出现发送方接收到三个重复确认,并不按照上一条执行,而是令
ssthresh=cwnd/2, cwnd=cwnd/2+3,进入拥塞避免状态(能收到重复报文,说明网络没那么拥堵,超时才是真的拥堵)
# 用户从输入域名到获取到信息过程中发生了什么
DNS 解析的过程:计算机先检查 DNS 缓存,如果没有缓存则向 DNS 服务器查询域名对应的 IP,查询的过程分为迭代和递归两种方式(主机向本地域名服务器查询是递归查询,本地域名服务器查询是迭代查询);面试官接着问了 DNS 基于什么协议,答案是 UDP,服务器一般使用 53 端口;
获取到 IP 以后就可以发包了,需要对包进行一层层的封装,自顶向下的封装顺序为:HTTP、TLS、TCP、IP;
HTTP 协议的内容大致为
HTTP/1.1 GET /;TLS 协议会进行 TLS 握手,主要是客户端、服务端交换密钥;
再往下是 TCP 和 UDP 协议。经典一问:TCP 和 UDP 的区别(TCP 面向连接、拥塞控制、流量控制),顺便还简单问了一下拥塞控制;
再往下就是 IP 层,主机会向向路由器发 IP 包、路由器根据路由表(用到了最长前缀匹配原则)和选路算法进行转发的过程;面试官又问了有那些选路算法(分为域内和域间协议,域内有 OSPF 和 RIP,域间使用 BGP);
再往下就是物理层了。
服务器返回 HTML 内容,前端接收到后开始渲染:
- 构建 DOM 树
- 构建 CSS 规则树
- 构建 render 树
- 布局(计算 element 在屏幕的位置)
- 绘制:使用 UI 绘制每个 element
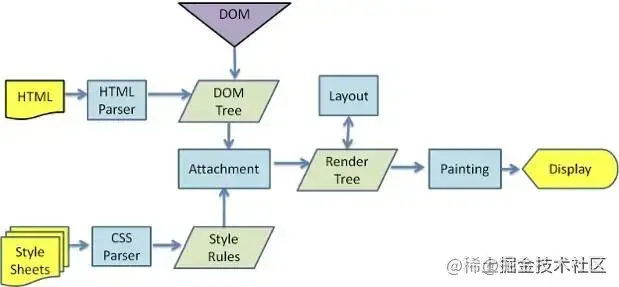
- 执行 JS 代码
- 如果有引用到其它地方的图片、JS、CSS 会再次进行 HTTP 请求,进行获取。
# 操作系统
# 进程和线程的区别
- 调度并分派的单位称为线程(或轻量级进程
LWP) - 资源所有权的单位称为进程
进程会创建进程控制块 (PCB),而线程是线程控制块 (TCB)。由于线程没有父子进程、资源控制等结构,所以 TCB 比 PCB 简单得多,这也导致线程的创建比进程的创建快得多,大概有一个数量级的区别。
这也是平时开发中,为了利用 CPU 多线程,我们常使用多线程开发,而不是多进程开发的原因。
# 用户态和内核态的区别,这样有什么好处
- 用户模式:优先权较少,用于运行用户程序
- 内核模式:优先权更高,用于运行内核,且某些指令、内存只能在特权模式下运行/访问,如:
- 读取/修改 PSW 等控制寄存器
- 原始 I/O 指令
- 内存管理相关
区分用户模式和内核模式的原因:保护 OS 和重要操作系统表不受程序干扰
# 用户级线程和内核级线程
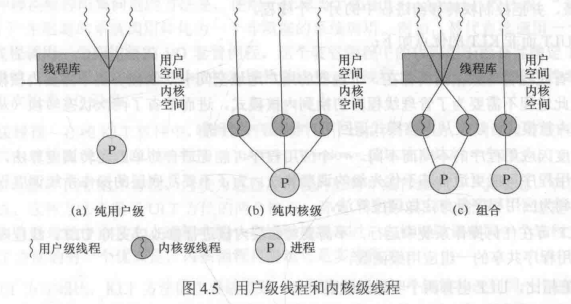
- 用户级线程:线程、线程的创建、销毁全部由库函数实现。内核不知道用户级线程的存在,依旧按照进程为单位进行调度。
- 优点:线程切换不需要内核模式,快;调度策略因应用程序不同而不同;可以运行在任何操作系统上
- 缺点:系统调用将阻塞同一进程中的其他线程;不能利用多处理器技术
- 内核级线程:管理线程的所有工作均由内核完成。 Windows是这种方法的一个例子。
- 优点:ULT 两个缺点反过来说;内核本身也可以是多线程的
- 缺点:ULT 三个优点反过来说;
# 进程七状态
- 运行
- 就绪
- 阻塞
- 就绪/挂起
- 阻塞/挂起
- New
- Exit
# 僵尸进程和孤儿进程
二者都是进程派生后,父子进程其中一个退出的情况。僵尸进程是子进程退出,孤儿进程是父进程退出。
孤儿进程:父进程派生出子进程。父进程退出,但子进程还在运行,子进程就被称为孤儿进程。Unix 系统下,孤儿进程会被 init 进程收养,并在孤儿进程退出后由 init 进程对它们完成状态收集工作。孤儿进程没有什么危害。
僵尸进程:父进程 fork 出子进程。子进程退出,父进程并没有获取子进程的状态信息,子进程的进程描述符仍然留在系统中,子进程被称为僵尸进程,在 htop 的状态一栏会被标记为 Z。大量僵尸进程会占用内存空间,需要把父进程 kill 掉,僵尸进程转为孤儿进程,进而被 init 回收。
# 进程调度算法
- 先来先服务
First Come First Served, FCFS - 时间片轮转
Round Robin, RR - 短进程优先
Shortest Process Next, SPN - 剩余时间最短优先
Shortest Remaining Time, SRT - 响应比高者优先
Highest Response Ratio Next, HRRN - 反馈
Feedback
# 进程切换算法
- 保存处理器上下文(寄存器)
- 更新当前进程的 PCB(状态、数据结构等变化)
- 将 PCB 的指针移至相应队列(就绪、阻塞、挂起等)
- 选择另一进程执行
# 中断是什么,软硬中断的区别是什么
- 中断:CPU 接受到外围硬件的异步信号 or 软件的同步信号,进行响应的软硬件处理
- 硬中断:CPU 接受到外围硬件的异步信号
- 软终端:CPU 接受到软件的同步信号(多为硬终端处理程序或进程调度程序发出)
- 区别:
- 硬中断会有中断控制器参与,外设->中断控制器->通过CPU针脚告诉CPU
- 软中断使用 CPU 指令触发
- 硬中断速度快
- 硬中断可以通过设置 CPU 屏蔽位来屏蔽
# 线程间通信方式
同一进程的线程共享内存地址空间,没有必要依赖 OS 进行通信,但要做好同步/互斥,保护共享的全局变量。
- 锁机制:三种常见的锁的实现包括互斥锁、读写锁、条件变量
- 互斥锁:提供了以排他方式防止数据结构被并发修改的方法
- 读写锁:允许多个线程同时读共享数据,而对写操作是互斥的
- 条件变量:可以以原子的方式阻塞进程,直到某个特定条件为真为止(对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用)
- 信号量 (Semaphore)
- 信号机制 (Signal):类似进程间的信号处理
# 进程间通信方式
进程间通信的方式——信号、管道、消息队列、共享内存 - 0giant - 博客园 (opens new window)
- 管道(Pipe),分为无名管道和有名管道,无名管道只能在父子进程或兄弟进程间通信,而有名管道就没有这个限制
- 信号(Signal)
- 消息队列(Message Queue)
- 共享内存(Shared Memory)
- 信号量(Semaphore)
- 套接字(Socket)
记住上面的六个词就可以对付 90% 的面试了,7% 的可能会问一下有名管道和无名管道的区别,剩下 3% 的面试可能每个都会问一下。
# 如何保证缓存一致性
缓存一致性就是保证内存和 CPU 缓存中的内容相同。
实现上有两种方案:Write-Through 和 Write-back。
Write-Through 在每次 CPU 更新缓存时会同时更新对应的内存,即把对缓存的更新穿透(through)到内存。
Write-Back 在每一行的缓存用一个 modified 标记了是否被修改。当这行缓存被修改时,不立即写入内存,而是标记该行缓存为 modified。当这行缓存将被替换时,就image.png会将这行内容写回(back)内存。
值得一提的是,这两种更新策略在使用 Redis 对数据库进行缓存时也会用于保证缓存一致性。编写一个 Cache Provider 提供对缓存和数据库的查询,程序不直接查询 Redis 或数据库,而是调用 Cache Provider 提供的接口进行读写,Cache Provider 可选择 Write-Through 或 Write-back 方案实现缓存一致性。
# 开发
# 深拷贝和浅拷贝
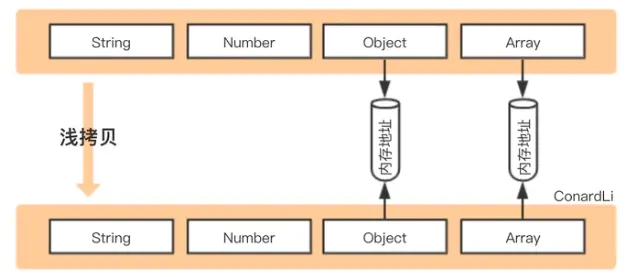
- 浅拷贝是创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址 ,所以如果其中一个对象改变了这个地址,就会影响到另一个对象。
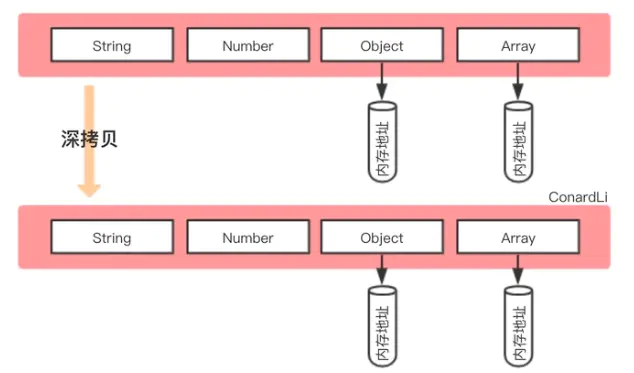
- 深拷贝是将一个对象从内存中完整的拷贝一份出来,从堆内存中开辟一个新的区域存放新对象,且修改新对象不会影响原对象。
# 如何进行调试
- 利用标准输出 / log 调试;
- 利用 IDE 单步调试;
- 利用
assert语句调试。
# 设计模式
设计模式- 廖雪峰的官方网站 (opens new window)
| 范围/目的 | 创建型模式 | 结构型模式 | 行为型模式 |
|---|---|---|---|
| 类模式 | 工厂方法 | (类)适配器 | 模板方法、解释器 |
| 对象模式 | 单例 原型 抽象工厂 建造者 | 代理 (对象)适配器 桥接 装饰 外观 享元 组合 | 策略 命令 职责链 状态 观察者 中介者 迭代器 访问者 备忘录 |
# 设计模式的原则
- 开闭原则:对扩展开放、对修改关闭
- 里氏替换原则 (opens new window):如果对父类的调用可以成功,对子类的调用也应该成功,这也是面向对象编程的基础
# 创建型模式
工厂方法:工厂方法的目的是使得创建对象和使用对象是分离的,并且客户端总是引用抽象工厂和抽象产品
┌─────────────┐ ┌─────────────┐
│ Product │ │ Factory │
└─────────────┘ └─────────────┘
▲ ▲
│ │
┌─────────────┐ ┌─────────────┐
│ ProductImpl │<─ ─ ─│ FactoryImpl │
└─────────────┘ └─────────────┘
抽象工厂:抽象工厂模式和工厂方法不太一样,它要解决的问题比较复杂,不但工厂是抽象的,产品是抽象的,而且有多个产品需要创建,因此,这个抽象工厂会对应到多个实际工厂,每个实际工厂负责创建多个实际产品:
┌────────┐
─ >│ProductA│
┌────────┐ ┌─────────┐ │ └────────┘
│ Client │─ ─>│ Factory │─ ─
└────────┘ └─────────┘ │ ┌────────┐
▲ ─ >│ProductB│
┌───────┴───────┐ └────────┘
│ │
┌─────────┐ ┌─────────┐
│Factory1 │ │Factory2 │
└─────────┘ └─────────┘
│ ┌─────────┐ │ ┌─────────┐
─ >│ProductA1│ ─ >│ProductA2│
│ └─────────┘ │ └─────────┘
┌─────────┐ ┌─────────┐
└ ─>│ProductB1│ └ ─>│ProductB2│
└─────────┘ └─────────┘
生成器模式(Builder):使用多个“小型”工厂来最终创建出一个完整对象。
原型模式(Prototype):创建新对象的时候,根据现有的一个原型来创建。
单例模式(Singleton):保证在一个进程中,某个类有且仅有一个实例。
# 结构型模式
适配器(Adapter):转换器,即负责将 A 类转换为 B 类的类
InputStreamReader 就是 Java 标准库提供的 Adapter,它负责把一个 InputStream 适配为 Reader。类似的还有 OutputStreamWriter。
桥接模式(Bridge):不要过度使用继承,而是优先拆分某些部件,使用组合的方式来扩展功能。
桥接前:
┌───────┐
│ Car │
└───────┘
▲
┌──────────────────┼───────────────────┐
│ │ │
┌───────┐ ┌───────┐ ┌───────┐
│BigCar │ │TinyCar│ │BossCar│
└───────┘ └───────┘ └───────┘
▲ ▲ ▲
│ │ │
│ ┌───────────────┐│ ┌───────────────┐│ ┌───────────────┐
├─│ BigFuelCar │├─│ TinyFuelCar │├─│ BossFuelCar │
│ └───────────────┘│ └───────────────┘│ └───────────────┘
│ ┌───────────────┐│ ┌───────────────┐│ ┌───────────────┐
├─│BigElectricCar │├─│TinyElectricCar│├─│BossElectricCar│
│ └───────────────┘│ └───────────────┘│ └───────────────┘
│ ┌───────────────┐│ ┌───────────────┐│ ┌───────────────┐
└─│ BigHybridCar │└─│ TinyHybridCar │└─│ BossHybridCar │
└───────────────┘ └───────────────┘ └───────────────┘
桥接后:
┌───────────┐
│ Car │
└───────────┘
▲
│
┌───────────┐ ┌─────────┐
│RefinedCar │ ─ ─ ─>│ Engine │
└───────────┘ └─────────┘
▲ ▲
┌────────┼────────┐ │ ┌──────────────┐
│ │ │ ├─│ FuelEngine │
┌───────┐┌───────┐┌───────┐ │ └──────────────┘
│BigCar ││TinyCar││BossCar│ │ ┌──────────────┐
└───────┘└───────┘└───────┘ ├─│ElectricEngine│
│ └──────────────┘
│ ┌──────────────┐
└─│ HybridEngine │
└──────────────┘
组合(Composite):将对象组合成树形结构以表示“部分-整体”的层次结构,使得用户对单个对象和组合对象的使用具有一致性。
public interface Node {
// 添加一个节点为子节点:
Node add(Node node);
// 获取子节点:
List<Node> children();
// 输出为XML:
String toXml();
}
装饰器(Decorator)模式,是一种在运行期动态给某个对象的实例增加功能的方法。类似于这样的方法
A decorator(A a);。
顺带一提,Python 的装饰器就玩得很好。
// 创建原始的数据源:
InputStream fis = new FileInputStream("test.gz");
// 增加缓冲功能:
InputStream bis = new BufferedInputStream(fis);
// 增加解压缩功能:
InputStream gis = new GZIPInputStream(bis);
// 或者一次性写成这样:
InputStream input = new GZIPInputStream( // 第二层装饰
new BufferedInputStream( // 第一层装饰
new FileInputStream("test.gz") // 核心功能
));
外观模式(Facade):将复杂的流程包装成一个函数并暴露给调用方。
// 将 register, openAccount, applyTaxCode 三个步骤包装成一个函数
public class Facade {
public Company openCompany(String name) {
Company c = this.admin.register(name);
String bankAccount = this.bank.openAccount(c.getId());
c.setBankAccount(bankAccount);
String taxCode = this.taxation.applyTaxCode(c.getId());
c.setTaxCode(taxCode);
return c;
}
}
享元模式(Flyweight):通过工厂方法创建对象,在工厂方法内部,很可能返回缓存的实例,而不是新创建实例,从而实现不可变实例的复用。如
Integer.valueOf()。
代理模式(Proxy):将 A 接口转换成 A 接口,可在调用 A 的方法前后加一些额外的代码,实现对 A 的控制。
# 装饰器和代理的区别
代理模式和装饰器模式的区别 - 知乎 (opens new window)
装饰器和代理很相似,都是接收 A 接口,返回 A 接口。其区别主要是思想上的区别:
装饰模式是为装饰的对象增强功能;
而代理模式对代理的对象施加控制,但不对对象本身的功能进行增强;
# 行为型模式
责任链模式(Chain of Responsibility)是一种处理请求的模式,它让多个处理器都有机会处理该请求,直到其中某个处理成功为止。责任链模式把多个处理器串成链,然后让请求在链上传递:
┌─────────┐
│ Request │
└─────────┘
│
┌ ─ ─ ─ ─ ┼ ─ ─ ─ ─ ┐
▼
│ ┌─────────────┐ │
│ ProcessorA │
│ └─────────────┘ │
│
│ ▼ │
┌─────────────┐
│ │ ProcessorB │ │
└─────────────┘
│ │ │
▼
│ ┌─────────────┐ │
│ ProcessorC │
│ └─────────────┘ │
│
└ ─ ─ ─ ─ ┼ ─ ─ ─ ─ ┘
│
▼
命令模式(Command)是指,把请求封装成一个命令,然后执行该命令。好处是可以对请求排队、记录请求日志,以及支持可撤销的操作。
解释器模式(Interpreter):如 Python 解释器、正则表达式匹配等。
迭代器模式(Iterator)
中介模式(Mediator):在多个组件的相互交互中,添加一个中介,所有组件和中介交互,实现组件间的松耦合。
备忘录模式(Memento),主要用于捕获一个对象的内部状态,以便在将来的某个时候恢复此状态。简单的实现是,编写这个类的
getState()和setState()方法,负责导出、导入信息即可。
观察者模式(Observer)又称发布-订阅模式(Publish-Subscribe, Pub/Sub):发布方搞一个
Observer数组;订阅操作就是将订阅者加入数组中;当发布方需要告知订阅者时,对数组中每个对象调用通知方法void onEvent(Event event);即可。
状态(State)
策略(Stategy):即排序算法时使用的 Comparator
模板方法(Template Method):使用抽象类定义流程,流程中的部分细节让子类实现
访问者(Visitor):包含对不同种类东西的访问方法(也可以理解成回调函数),如对文件和文件夹的访问方法
# Redis
# 缓存穿透、击穿、雪崩
- 缓存雪崩:大批数据的缓存同时过期,大量请求打到数据库,造成整个数据库服务崩溃(依赖该数据库的其他服务也接连崩溃)
- 预防方法:设置过期时间时加一个随机量
- 抢救方法:熔断机制,当流量达到阈值时拒绝请求,至少让一部分请求能正常工作,其他用户刷新几次也能得到结果
- 缓存击穿:某一条热点数据过期的瞬间, 大量请求打到数据库,造成整个数据库服务崩溃
- 预防方案:设置热点数据不过期,或使用互斥锁,降低请求同一条数据的并发量
- 缓存穿透:大量请求中 key 不存在,缓存自然不存在,导致大量请求打到数据库
- 预防方案:将无效的 key 存到 Redis 中;使用布隆过滤器 (opens new window)(即多重哈希表)。
# Redis 除了缓存还能做什么
Redis除了做缓存,还能做什么 - 豆奶特 (opens new window)
# 消息队列
# 消息队列的好处
消息队列基础常见面试题总结 | JavaGuide (opens new window)
- 减少系统响应时间(不再等待请求数据成功,而是直接返回)
- 削峰/限流
- 降低系统耦合性(模块之间不再直接调用,而是从 MQ 里存取数据)
# 消息队列模型
比较常见的就是:点对点模式(一个生产者对一个消费者)、发布/订阅(一个生产者对多个消费者)。
# 分布式
分布式知识点 | JavaGuide (opens new window)
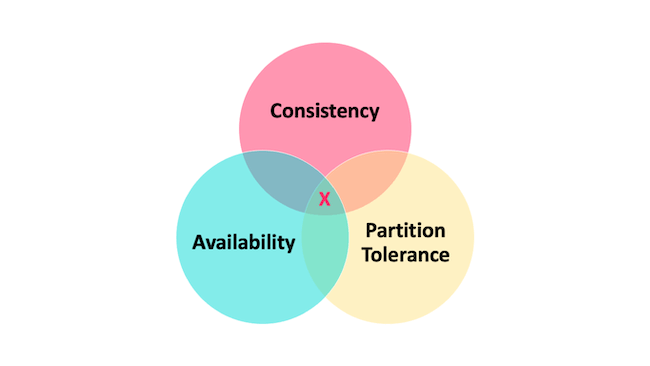
# CAP 理论
- C: Consistency (一致性), 所有节点返回相同的数据
- A: Availability (可用性), 非故障节点能够在合理的时间内返回正确的数据
- P: Partial Tolerance(分区容错性), 即使由于网络故障, 某些节点之间不能通信, 也能对外提供服务
CAP 理论简单的说就是:当发生网络分区时,一致性和可用性只能 2 选 1。也就是说,只能选 CP 或 AP。
以常见的可以作为注册中心的组件为例:
- Zookeeper 保证 CP:任何时候读 Zookeeper 都能得到一致的结果,但不保证每次请求的可用性(如选举 leader 时,服务不可用);
- Eureka 保证 AP:每个节点都都是平等的,都可以返回数据,但返回的数据不保证是最新的;
- Nacos 支持 CP 和 AP 两种模式。
# 一致性理论 / BASE 理论
上面说到大多数分布式框架都是保证 CP 或者 AP 的。其实还有一种情况,在保证 P 的前提下,在 A 和 C 之间进行平衡。一致性理论抛弃了 C 的强一致性(任何时刻都一致),转为追求最终一致性(最后一致即可),并在这个平衡中获得了一部分的 A,这种 A 称为“主要可用”。
一致性理论的三要素:
- BA: Basically Available (基本可用), 响应时间可以变慢, 非核心功能可以不工作
- S: Soft state (软状态), 即数据从不一致到一致的过程的中间状态
- E: Eventually Consistent (最终一致性), 即系统保证一定时间内数据到达一致性
一致性分为三种级别,由强到弱依次为:强一致性、最终一致性、弱一致性:
- 强一致性:系统在任何时间的数据都是一致的
- 最终一致性:系统保证一定时间内达到数据一致
- 弱一致性:系统尽快达到数据一致(也就是没有做任何保证)
业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。
最终一致性有三种实现:读时修复、写时修复、异步修复:
- 读时修复:系统读取数据时,如果检测到不一致,则进行修复
- 写时修复:系统写入数据时,如果失败,则定时重传
- 异步修复:系统定时对账,检测数据一致性
# Raft 算法
Paxos 算法和 Raft 算法都是分布式系统共识算法。 Paxos 算法比较复杂,而 Raft 算法是基于 Paxos 算法改进而来,直接学习 Raft 算法即可。
# 共识算法的基本原理
共识算法的目标是:即使面对故障,多个服务器也能在共享状态上达成一致。
为了达到这个目的,一般通过复制日志来实现。只要所有服务器的日志的内容和顺序都相同,就能保证它们执行了相同的命令,这对于确定性图灵机来说就是执行结果相同。
# 共识算法的特点
- 安全
- 高可用
- 一致性不依赖时序(错误的时钟和消息延迟不会影响一致性,只可能影响可用性)
- 不会被少数运行缓慢的服务器影响性能
# Raft 算法 -- 选举 Leader
Raft 算法的核心为两个部分:选举 Leader 和 日志复制。
集群里的每个服务器就称为一个节点。分为三种类型:
Leader,即主服务器。被选举为 Leader 的服务器将在其任期内负责和客户端交互、将日志分发给 Follower。Candicate,为 Leader 选举中的候选人。在选举 Leader期间,所有服务器都可以成为 Candidate 竞选 Leader。Follower即从服务器
任期:Raft 算法将时间划分为多个任期(term),每个任期会用一个自增的数字 id 表示。每个任期开始时都需要竞选 Leader,成功当选的服务器会在该任期内担任 Leader。
服务器间的交互都会带上任期号,确保交互的双方是在同一个任期内。如果某方的 term 较小,说明该服务器的信息过期了。
- 如果 Follower 发现本地的
term过期了,则会更新到新的term。 - 如果 Leader 或 Candidate 发现本地的
term过期了,则会退回为 Follower。 - 如果服务器发现对方的
term过期了,则会拒绝此次请求。
一个选举过程中可能出现以下几种情形:
给别人投票:如果一台 Follower 收到 Leader 或 Candidate 的心跳包,则会一直保持为 Follower。
参加选举:如果 Follower 一直没有收到(超时),则会开始一次选举:自增本地的 term 并变为 Candidate,并向其它服务器周期性发送心跳包。
选举成功:如果 Candidate 在一个任期内收到了集群内的过半选票,则成为 Leader。
Candidate 收到 Candidate 或 Leader 的心跳包:此时需要根据双方 term 大小分情况讨论:如果接收到的 term 大于或等于自身的 term,则本 Candidate 转化为 Follower 并对发送心跳包的服务器投票;如果接受到的 term 小于自身的 term,则拒绝该请求。
如果同一时间出现多名 Candidate,导致没有 Candidate 获得大多数选票,导致多个服务器同时开始新一轮选票,就陷入了活锁。Raft 的解决方案是,每个服务器的每次超时都是随机的 150ms~300ms,于是最先超时的服务器会率先更新 term,并向其它服务器发送新 term 的心跳包。
# Raft 算法 -- 日志复制
选举过程中服务器集群处于不可用的状态,因为没有 Leader。在完成选举后,选举出的 Leader 就会负责和客户端进行交互。
日志复制的流程如下:
Leader 收到客户端请求后,会生成一个条目(entry)。一个 entry 包含当前 term、一个自增的索引 index 和客户端的指令 cmd。
生成 entry 后,Leader 将其追加到自己的日志末尾,并向所有节点广播该 entry,要求 Follower 也将其追加到自己的日志末尾。如果过半 Follower 接受该 entry,则 Leader 提交该 entry,将 entry 应用到自己的状态机中,并向客户端返回执行结果。
Raft 算法保证日志的以下两个特性:
- 如果两个日志中的两个
entry具有相同的term和index,则它们的cmd也相同。 - 如果两个日志中的两个
entry具有相同的term和index,则它们前面的所有entries都相同。
第一个特性是因为只有 leader 可以生成日志,且一个 term 只有一个 leader。
第二个特性需要 Leader 每次要求 Follower 追加日志时,同时进行一致性检查来保证。Leader 发送追加日志请求时,除了发送本次完整的 entry 以外,还会发送前面一条 entry 的 term 和 index。Follower 收到后对本地最新一条 entry 的 term 和 index 进行检查,如果相同才会接受。(既然每次添加日志时保证前一条都相同,由数学归纳法可知前面所有的日志都相同)
正常情况下一致性检查不会失败,但在节点崩溃时会出现日志不一致。Follower 的日志相较现任 Leader 的日志可能多、可能少、甚至可能既多一部分又少一部分。
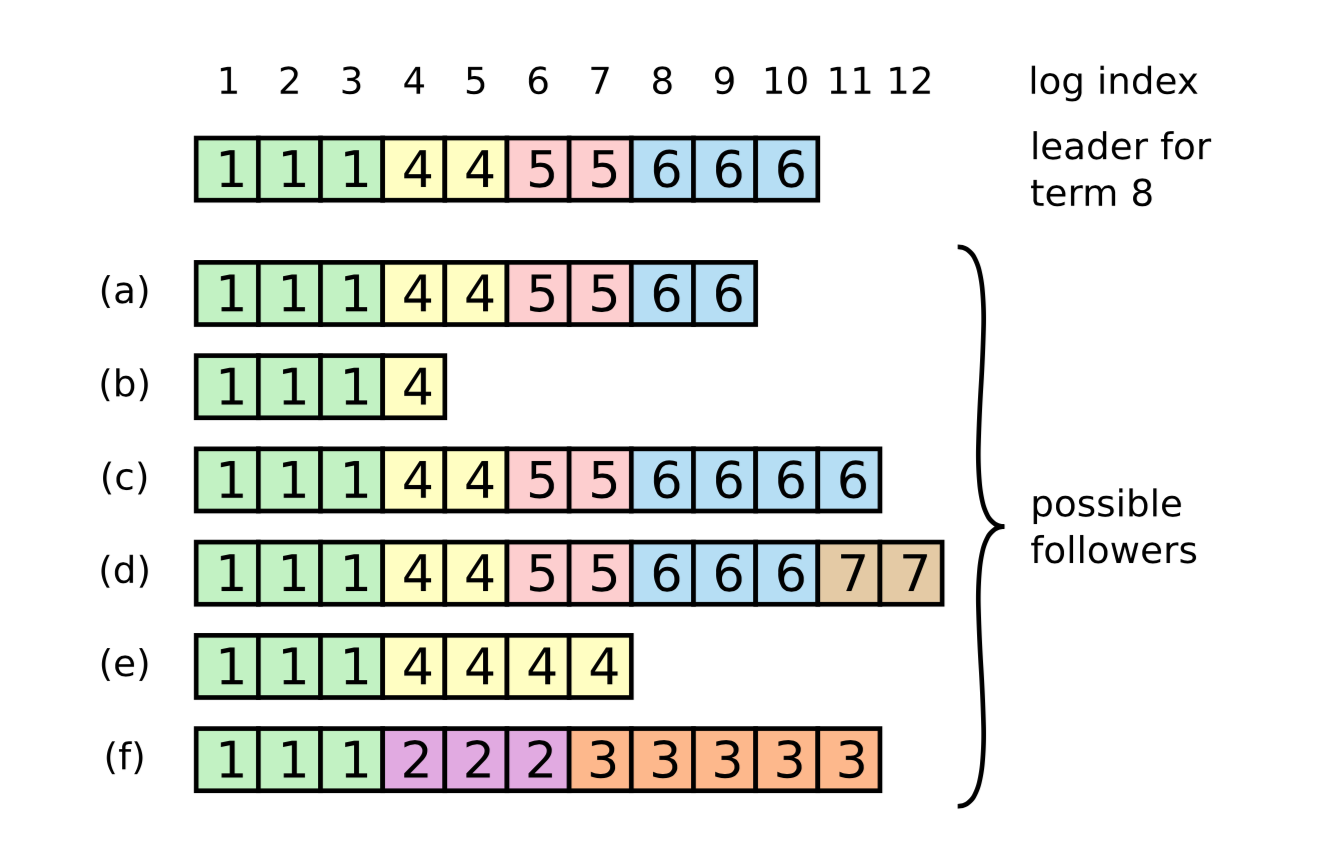
- a 和 b 是 Follower 的日志更少的情况,很好理解(Follower 曾掉线)
- c 和 d 是 Follower 的日志更多的情况。这种情况可能是现任 Leader 向部分服务器发送了请求,但由于未过半,因此没有提交该请求;也可能现任 Leader 在
term 6掉线了,新的服务器 d 已经在term 7推选出新的 Leader; - e 和 f 是 Follower 的日志多一部分又少一部分的情况。比如服务器 f 在任期 2 当选 Leader,并追加了一些日志,但在提交前崩溃了;重启后又在任期 3 当选 Leader,并追加了一些日志,然后又又在提交前崩溃了。
Raft 算法处理日志不一致的方法直接粗暴:强制使用 Leader 的日志覆盖 Follower 的(即现任 Leader 永远是对的)。换句话说,Leader 和 Follower 找到两份日志最后一致的地方,Follower 删掉之后不一致的部分,然后将 Leader 之后不一致的部分追加到末尾。因此,接下来需要讨论 Leader 和 Follower 如何寻找最后一致的地方。
Leader 会为每个 Follower 维护 nextIndex 表示下一个需要向其发送的 entry 的 index。当 Leader 刚上任时,它会初始化所有的 nextIndex 为自己本地最后一条 entry 的 index + 1。如果某个 Follower 的日志和 Leader 有不一致,下次 Leader 追加日志时的一致性检查会失败。失败后,Leader 会将 nextIndex 减小后重试。若干次重试后,Leader 将 nextIndex 退回到一致的日志条目 index + 1,此时一致性检查成功,Follower 将这之后的日志条目都删掉,并将 Leader 刚发送的日志条目追加到自己的日志中。之后的一致性检查会一直成功,Leader 会根据 nextIndex 将每条日志条目发送给 Follower。
优化 1:在确定日志一致性之前,Leader 可以只发送不包含新的日志条目,只包含前一条的 term 和 index 的请求,可以节省带宽。
优化 2:Follower 拒绝请求时,可以一并发送该冲突日志的 term,和自己本地的该 term 的最早的 index,Leader 即可直接将 nextIndex 减少到该 index。
# Raft 算法 -- 为了保证 Leader 拥有所有已提交日志而产生的选举限制
上述部分的选举 Leader 和日志复制即是 Raft 的整体思路,但还有一个小的细节没有处理,本段即是叙述 Raft 如何处理这个细节。
在任何基于 Leader 的一致性算法中,Leader 都需要存储所有已提交的日志条目。最直观的思路是,Follower 将已提交的日志条目回传给 Leader,但这种思路在实现时非常麻烦。
Raft 采用的方法很有意思:在竞选阶段,Follower 不会支持已提交日志比自己少的 Candidate。在“日志需要被发送给过半数的服务器才会被提交”的前提下,超过半数的 Follower 不会支持没有完整已提交日志的 Candidate,该 Candidate 自然也不会赢得竞选、成为 Leader。
# todo
https://javaguide.cn/distributed-system/api-gateway.html#%E4%BD%95%E4%B8%BA%E7%BD%91%E5%85%B3-%E4%B8%BA%E4%BB%80%E4%B9%88%E8%A6%81%E7%BD%91%E5%85%B3
# Linux 命令
| 命令 | 用途 |
|---|---|
top | 任务管理器 |
free | 查看剩余内存等(不过为什么不用 top 呢) |
ps | 查看进程,可使用 ps aux | grep '<process_name>' 查 pid |
kill -9 <pid> | 杀进程 |
lsof -i:8000 | 查看 8000 端口的占用进程 |
nload | 查看流量大小 |
wc | (word count) 统计文件的字数、行数、字符数 |
tail --follow | 实时输出(日志)文件内容 |
journalctl -f -u <unit.service> | 实时输出日志内容 |
grep word file.txt | 在 find.txt 查找 word 字符串,-i 大小写不敏感 |
find <directory> -name 'file.txt' | 在目录下查找 file.txt |
df -h | 查看文件剩余空间 |
# 低频考点
以下是低频考点,但是在真实面试中问过一次,读者可以按需掌握。
# C++
# C 语言获取当前文件夹、函数名、行数
中望龙腾 C++ 岗笔试考过。
#include<iostream>
#include<direct.h>
using namespace std;
int main()
{
cout << _getcwd(0, 0) << endl // 获取当前文件夹
<< "__FUNCSIG__:" << __FUNCSIG__ << endl // 获取函数完整签名
<< "__FUNCTION__:" << __FUNCTION__ << endl // 获取函数名
<< "__LINE__:" << __LINE__; // 获取行数
}
输出:
C:\Users\liu\Desktop\test\cpp
__FUNCSIG__:int __cdecl main(void)
__FUNCTION__:main
__LINE__:11
# C 语言字节对齐
# cv 限定符
cv(const 与 volatile)类型限定符 | cppreference.com (opens new window)
cv 限定符是 const 和 volatile 的合称。
当对象最初被创建时,所用的 cv 限定符决定对象的常量性或易变性。
const 大家都懂,就是不能修改的常量 (constant),直接修改会编译报错,间接修改(如利用 const_cast<int&> 等手段)为未定义行为。还有一点,就是写为 const 之后,编译器会进行优化。
而 volatile 翻译过来是“易变”的,表明该变量可能通过软件甚至硬件方式变化。这会阻止编译器对这个变量进行任何优化,包括但不限于:不会将变量放到寄存器中;不会对 const volatile 变量当做 const 进行优化。(不过,CPU 仍可以将变量放入缓存中,因为缓存对程序员是透明的)
代码例子见 const_cast 部分。
# static 用处
C 语言的 static 有三个用处:
- 对
函数内变量使用,扩展其生存期; - 对
函数外变量和函数使用,使其他文件不能通过extern访问到该变量/函数(默认是可以的); - 对
类的成员/方法使用,使得该变量/函数属于类(其他的都是属于每个对象),可以直接由类名Classname::调用;
# 禁止继承
C++ 11 引入了 final 关键字。
class A final {
};
class B : public A {
}; // error: 不能选择 final 类作为基类
# 禁止拷贝构造函数和赋值构造函数
C++11 加入了 = delete 控制类默认函数。
class Thing
{
public:
Thing(const Thing&) = delete;
Thing& operator = (const Thing&) = delete;
};
int main(int)
{
Thing t1; // 错误 E0291:类 "Thing" 不存在默认构造函数
Thing t2(t1); // 错误 E1776:无法引用 函数 "Thing::Thing(const Thing &)" (已声明 所在行数:4) -- 它是已删除的函数
Thing t2 = t1; // 错误 E1776:无法引用 函数 "Thing::Thing(const Thing &)" (已声明 所在行数:4) -- 它是已删除的函数
return 0;
}
C++98 前可以定义为 private。
class Thing
{
public:
private:
Thing (const Thing &);
Thing & operator = (const Thing &);
};
int main(int)
{
Thing t1;
Thing t2(t1); //error C2248: “Thing::Thing”: 无法访问 private 成员
Thing t2 = t1; //error C2248: “Thing::Thing”: 无法访问 private 成员
return 0;
}
# std::vector 和 std::array
- vector 和 array 都是可以通过
[]访问下标对应元素的数组; - vector 是变长数组,可以通过
push_backinsert和erase修数组大小。(注意insert和erase都是 的); - C++ vector 内存分配与回收机制 (opens new window);
- array 则是 C++11 引入的、对标准数组的封装,是定长数组。
# Lambda 捕获值列表
Modern C++ zh-cn (opens new window)
分为三种:
- 值捕获
[value]或[=value]:与参数传值类似,值捕获的前提是变量可以拷贝。不同之处则在于,被捕获的变量在 Lambda 表达式被创建时拷贝, 而非调用时才拷贝。 - 引用捕获
[&value]:与引用传参类似,引用捕获保存的是引用,值会发生变化。 - 隐式捕获
[=]或[&]:手动书写捕获列表有时候是非常复杂的,这种机械性的工作可以交给编译器来处理,这时候可以在捕获列表中写一个&或=向编译器声明采用引用捕获或者值捕获。(很多地方说的是捕获this,我觉得还是这个好理解一些,毕竟如果在 main 函数中,也没有this一说)
总结一下,捕获提供了 Lambda 表达式对外部值进行使用的功能,捕获列表的最常用的四种形式可以是:
[]空捕获列表[name1, name2, ...]捕获一系列变量[&]引用捕获, 让编译器自行推导引用列表[=]值捕获, 让编译器自行推导值捕获列表
# 数据结构
# 堆的复杂度
面腾讯的时候被问到,建堆的复杂度是多少,还好之前写过博客,还有一点点印象不是 ,而是 。回顾了一下博客,果然是,顺便重温了一下证明。
# 计算机网络
# TIME_WAIT 快速回收与复用
time-wait快速回收与复用 - rosewind的博客 | BY Blog (opens new window)
time_wait的快速回收和重用 (opens new window)
NAT环境下tcp_timestamps问题_〓☆〓 清风徐来918 (QQ:89617663)-CSDN博客_tcp_timestamps (opens new window)
这是腾讯主管问的问题,一般第二次考到的概率很小,但作为一个知识了解也不错。
TIME_WAIT 状态产生的原因在上面部分提到了,这里不再赘述。如果 TIME_WAIT 太多,导致无法对外建立新 TCP 连接。
在 Linux 下,可以从系统层面,或从应用程序层面解决这个问题。
系统层面上,也有三种方法。
一是提高 tcp_max_tw_buckets,就能接受更多的 TIME_WAIT,但是治标不治本。
二是开启 TIME_WAIT 快速回收 tcp_tw_recycle(需同时开启 tcp_timestamps,系统默认开启)。原理是在 TCP 报文中加入时间戳(时间戳在 TCP 报文中的可选字段),然后系统缓存每个连接最新的时间戳。如果收到的 TCP 报文的时间戳早于缓存值,就丢弃数据包 (RFC1323)。
快速回收的问题在于,搭配 NAT 可能会出现问题。现在很多公司都用 LVS 做负载均衡,通常是前面一台 LVS,后面多台后端服务器,这其实就是 NAT,当请求到达 LVS 后,它修改地址数据后便转发给后端服务器,但不会修改时间戳数据,对于后端服务器来说,请求的源地址就是 LVS 的地址,加上端口会复用,所以从后端服务器的角度看,原本不同客户端的请求经过 LVS 的转发,就可能会被认为是同一个连接,加之不同客户端的时间可能不一致,所以就会出现时间戳错乱的现象,于是后面的数据包就被丢弃了,具体的表现通常是是客户端明明发送的 SYN,但服务端就是不响应 ACK。如果服务器身处 NAT 环境,安全起见,通常要禁止 tcp_tw_recycle,至于TIME_WAIT连接过多的问题,可以通过 TIME_WAIT 复用解决。
三是开启 TIME_WAIT 复用 tcp_tw_reuse(也需要同时开启 tcp_timestamps)另外复用也是也是有条件的:协议认为复用是安全的。与 tcp_tw_recycle 选项相比,本选项一般不会带来副作用。
应用层面上,有两种解决办法:一是将 TCP 短连接改造为长连接,二是快速关闭 socket。
# HTTP 1.0 vs 1.1 vs 2.0 vs 3.0
参考:关于队头阻塞(Head-of-Line blocking),看这一篇就足够了 - 知乎 (opens new window)
- HTTP/1.1:通过使用 TCP 长链接,可以在一个 TCP 链接上以流水线的形式发送多个文件
- HTTP/2:通过分帧,解决了 HTTP/1.1 在 HTTP 协议层的队头阻塞(两个文件可以交叉传输,而不是先发送的大文件必须全部收到后,才能发送后面的小文件)
- HTTP/3:通过改用基于 UDP 的 QUIC,解决了 HTTP/2 在 TCP 协议层的队头阻塞(如果 TCP 层面发生了丢包,HTTP 层不能先拿到后面的包)。不过 HTTP/3 只有在丢包率很高的网络下才会有显著的优势
# HTTP 状态码
- 1xx:
102 Processing (WebDAV)用于表明 WebDAV 服务器收到了请求,但请求的操作比较费时,服务器正在处理(如遍历当前文件夹)。为了防止客户端 TCP 超时、假设请求丢失,于是服务器可以发送一个没有信息的 102 应答。
- 2xx:
200 OK201 Created202 Accepted表示正在进行一个异步操作。用于 1. 重置密码时,服务器返回202,然后将重置邮件发送给邮箱;2. Onedrive 分段上传时 (opens new window),如果完成了一部分的上传,会返回202。204 No Content206 Partial Content
- 3xx:
- 301 302 307 308 见后
304 Not Modified
- 4xx:
400 Bad Request401 Unauthorized403 Forbidden404 Not Found405 Method Not Allowed409 Conflict415 Unsupported Media Type
- 5xx:
500 Internal Server Error502 Bad Gateway常见于 Nginx 反代的服务出锅了504 Gateway Timeout
永久重定向 Permanently | 暂时重定向 Temporarily | |
|---|---|---|
允许将 POST 方法改为 GET | 301 Moved Permanently | 302 Moved Temporarily |
不允许将 POST 方法改为 GET | 308 Permanent Redirect | 307 Temporary Redirect |
# HTTPS 原理及握手过程
SSL/TLS协议运行机制的概述 - 阮一峰的网络日志 (opens new window)
- 客户端发送:ClientHello + 随机数 client random
- 服务端发送:ServerHello + 随机数 server random + 证书
- (客户端验证证书有效性)
- 客户端发送:随机数 premaster secret (经公钥加密)
- (服务器和客户端使用三个随机数生成一个会话密钥)
- 客户端发送:finished (经会话密钥加密)
- 服务端发送:finished (经会话密钥加密)
# Nginx
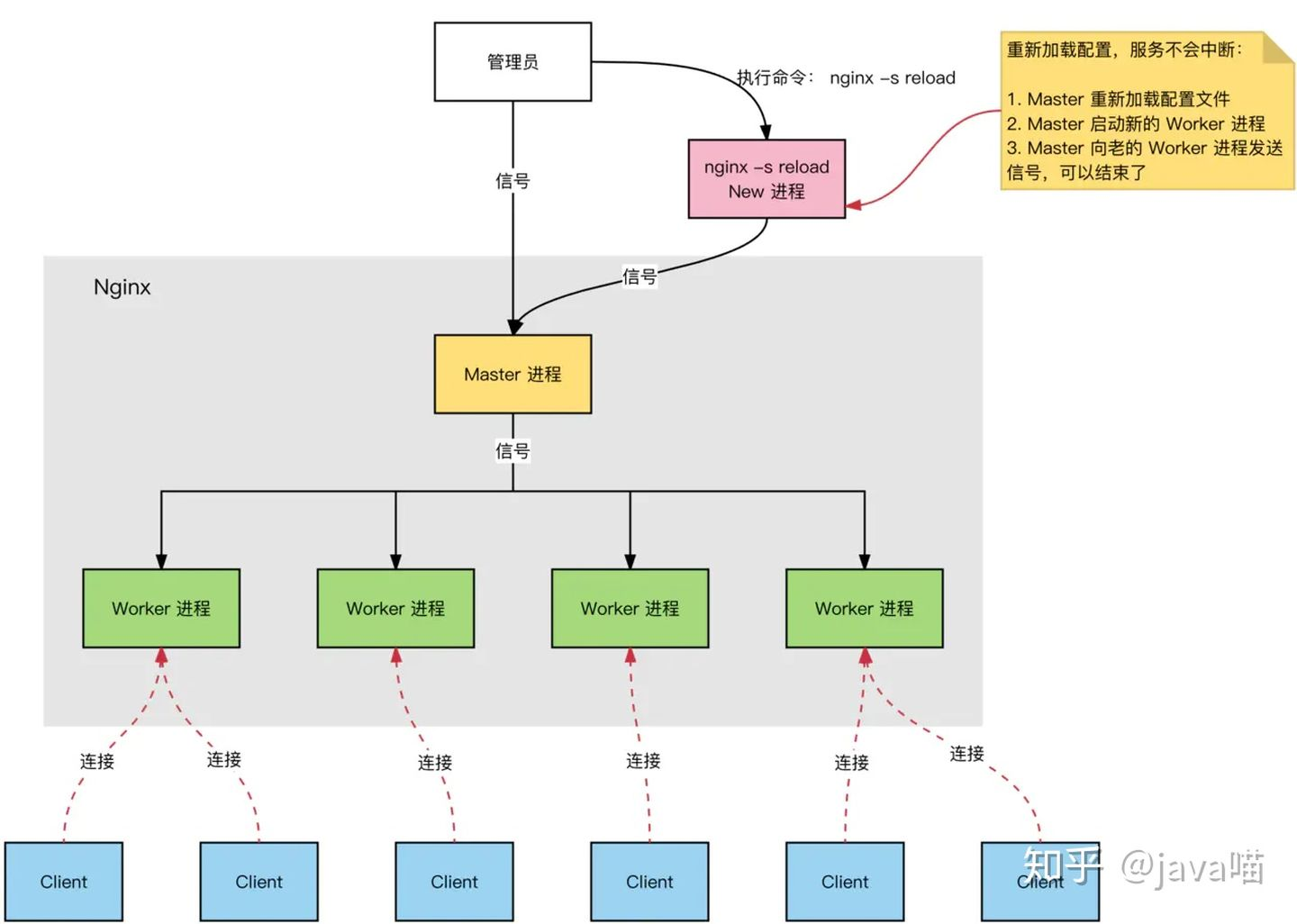
Nginx为什么快到根本停不下来? - 知乎 (opens new window)
# Nginx 多进程
一个 Master 进程配合多个 Worker 进程
- Master 进程:管理 Worker 进程
- 对外接口:接收外部的操作(信号)
- 对内转发:根据外部的操作的不同,通过信号管理 Worker
- 监控:监控 worker 进程的运行状态,worker 进程异常终止后,自动重启 worker 进程
- Worker 进程:所有 Worker 进程都是平等的
- 实际处理:网络请求,由 Worker 进程处理;
- Worker 进程数量:可在 nginx.conf 中配置,一般设置为核心数;
# Nginx IO 多路复用
Nginx 使用epoll 多路复用
# Nginx 均衡负载算法
共五种:
- 轮询 (Round Robin)
- 加权轮训,权越大表示服务器的能力越强,能承受更大负载
- 最小连接数 (Least Connections)
- IP Hash,保证同 IP 映射到同一服务器,在集群不同享 Session 时很好用
- URL Hash,保证同 URL 映射到同一服务器,在有 URL 缓存时效率高
# Docker
# Docker 底层
Docker 的底层技术 (opens new window)
概要:Docker 使用 Linux 命名空间实现容器的隔离,使用控制组实现对容器的资源限制,使用联合文件系统提高存储效率。
和虚拟机不同,Docker 进程和宿主机进程共用一个内核和某些系统库等。而彼此各个进程的方法是 Linux 上的命名空间 (Namespaces)。
Docker 使用名称空间来为容器提供隔离的工作空间。当一个容器运行时,Docker 就会为该容器创建一系列的名称空间,并为名称空间提供一层隔离。
Docker 引擎也依赖另一项叫 Control groups (cgroups,控制组) 的技术。控制组可以对程序进行资源限定,并允许 Docker 引擎在容器间进行硬件资源共享以及随时进行限制和约束,如内存等。
联合文件系统 (UnionFS) 是一种分层、轻量级并且高性能的文件系统,它支持将文件系统的修改作为一次提交来一层层地叠加。不同 Docker 容器可以共享基础的文件系统层,与自己独有的改动层一起使用,可以大大提高存储效率。
# I/O 多路复用
I/O 多路复用是一种同步 I/O 模型,实现一个线程监听多个文件句柄;一旦某个文件句柄就绪,就能通知应用程序进行读写操作。没有文件句柄就绪时就会阻塞应用程序。
I/O 多路复用提供了三种实现:select、poll 和 epoll。
int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select 函数将需要监听的 file descriptors(fd) 传给 select 函数,当其中一个就绪后函数就返回。
select 优点:跨平台 select 缺点:
- 底层是通过轮询数组来实现的,时间复杂度为
O(n),且监听的 fd 有数量限制 - 每次调用 select 时都需要把 fd 从用户态复制到内核态
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
poll 在使用上和 select 没什么区别。
poll 优点:改用轮询链表实现,监听的 fd 就没有数量限制了 poll 缺点:
- 依旧是轮询链表,时间复杂度依旧是
O(n)。 - 在每次调用时依旧需要把 fd 从用户态复制到内核态
int epoll_create(int size);//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
epoll 的使用稍微复杂一些,使用事件来驱动。
epoll 优点:
- 使用哈希表来实现,优点是时间复杂度降低到
O(1),且依旧没有大小限制 - 在最开始调用
epoll_ctl时会将 fd 态从用户态复制到内核态,之后每次调用epoll_wait进行等待时都不需要复制。
epoll 缺点:最开始需要调用 epoll_create 在 OS 中创建一个 fd。
# 零拷贝
深入剖析Linux IO原理和几种零拷贝机制的实现 - 知乎 (opens new window)
零拷贝指的是在数据从网络等设备到用户程序空间传递的作用中,实现 CPU 的零参与,消除 CPU 在这方面的负载,也减少了拷贝次数。用到的主要技术是 DMA + 内存区域映射。
# DMA
直接内存存取(Direct Memory Access,DMA)允许网络、磁盘、显卡等设备直接绕过 CPU 访问内存。
除了开始和结束需要 CPU 参与(向 DMA 控制器发出、接收信号)以外,其余操作都是由 DMA 控制器完成的。
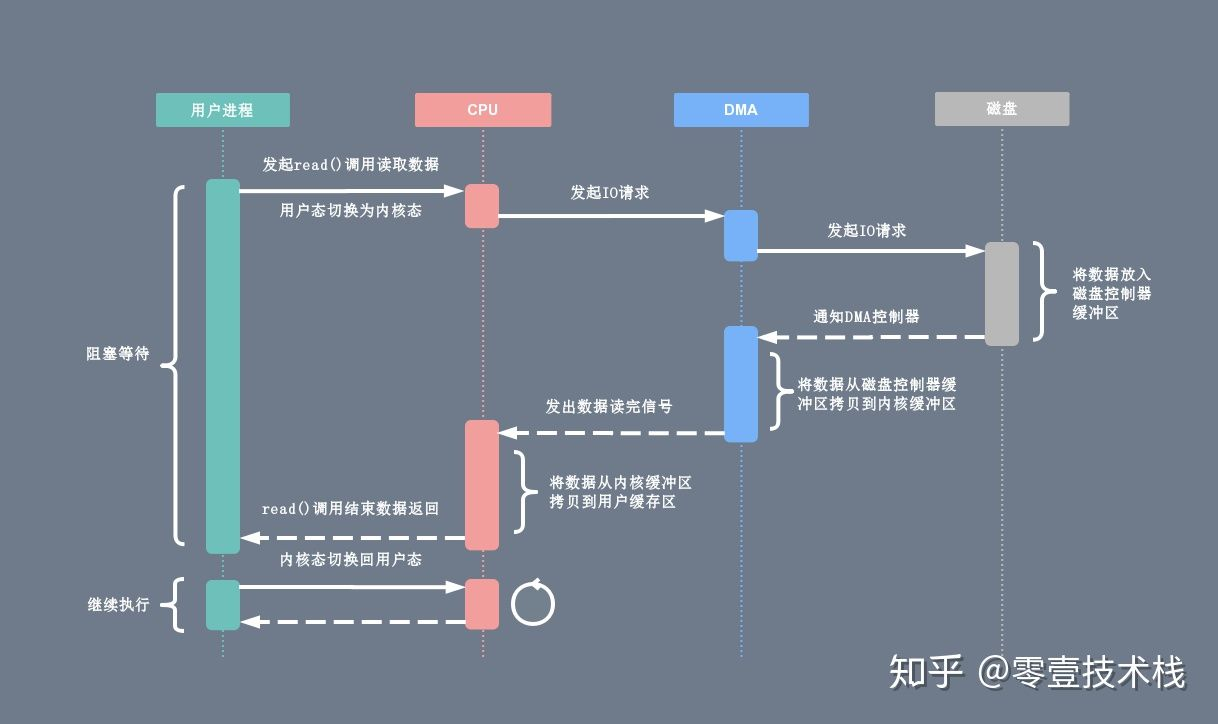
图中可以看出,CPU 仍需要在内存的内核缓冲区和用户缓冲区间进行拷贝(如下图)。为了解决这个问题,有好几种方案,用于解决不同的场景。
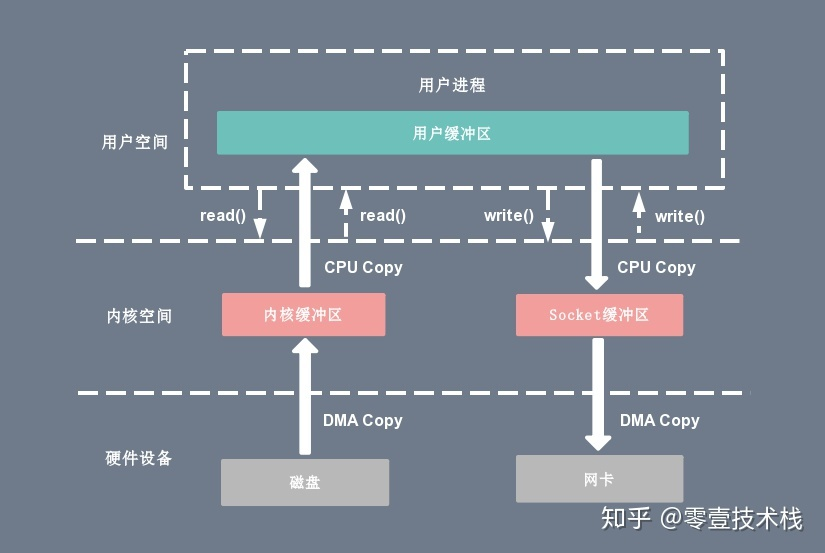
# mmap + write
mmap 是 Linux 提供的一种内存映射文件方法,能将“内核读缓冲区”映射到“用户空间的缓冲区”,减少一次复制,但写的时候仍然需要复制,如下图:
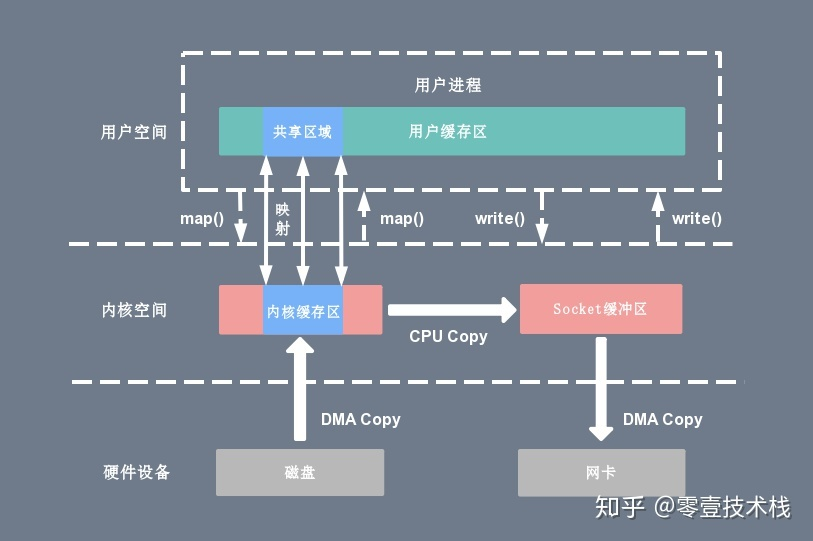
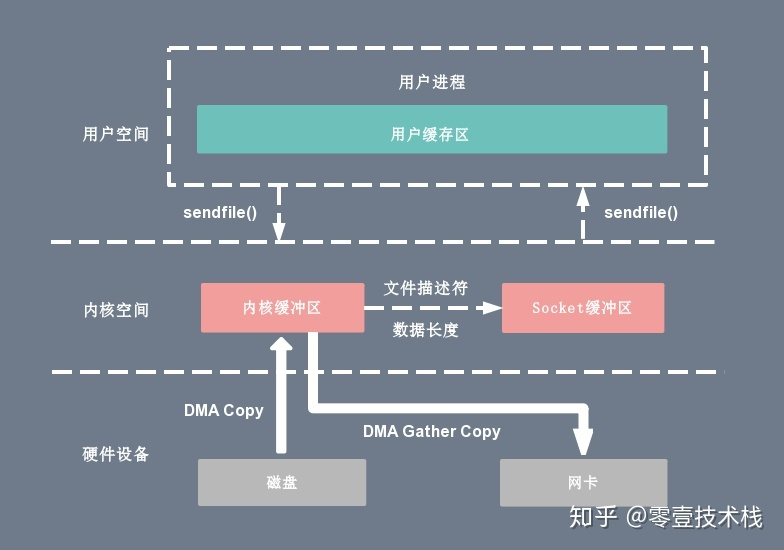
# sendfile + DMA gather copy
sendfile + DMA gather copy 用于进程不需要读写数据,仅将数据原封不动地从一个外设拷贝到另一个外设中。sendfile 可以让数据直接在内核空间中进行传输(从“内核读缓冲区”到“内核写缓冲区”)。而 DMA gather copy 技术可以内核读缓冲区“映射”到内存写缓冲区,从而实现内存之间的零次拷贝。当然缺点是进程无法读写这部分数据。